
РЕСУРСИ ГУРТУ R2U ДЛЯ АВТОМАТИЧНОГО ОПРАЦЮВАННЯ ПРИРОДНОЇ МОВИ

У нинішню епоху стрімкого розвитку інформаційних технологій зростає потреба в засобах автоматичного опрацювання природної мови та в оперативному доступі до значних масивів мовних даних, зокрема в машиночитному форматі. Гостро актуальним є формування комп’ютерно-лінгвістичної «екосистеми» для української мови — інструментарію й мовних даних, що їх фахівці створюють і удоступнюють іншим дослідникам, розробникам і програмувальникам.
Без такої екосистеми чимало проектів доводиться починати «з нуля» й важко уникнути дублювання роботи — наприклад, укладання словника словозміни, який виявляється доконечно потрібним для багатьох завдань.
Деякі важливі елементи цієї екосистеми вже створено — наприклад, комп’ютерний морфемно-словотвірний фонд української мови (роботу над ним розпочато ще наприкінці 1980-х років під керівництвом Н.Ф. Клименко в Інституті мовознавства ім. О.О. Потебні й згодом продовжено в Інституті української мови НАНУ), комп’ютерний фонд інновацій у сучасній українській мові (Інститут української мови НАНУ, керівник Є.А. Карпіловська), доробок лабораторії комп’ютерної лінгвістики Інституту філології Київського національного університету імені Тараса Шевченка (керівник Н.П. Дарчук) та інші, однак багатьох ресурсів ще бракує.
На заповнення цих прогалин у комп’ютерній лінгвістиці й комп’ютерній лексикографії й спрямовано працю гурту r2u.
Далі я розкажу про такі ресурси й засоби: словникові вебсайти r2u.org.ua й e2u.org.ua, Великий електронний словник української мови (ВЕСУМ), засіб перевіряння орфографії, граматики й стилю «Правописник LanguageTool» та Браунський український корпус (БрУК).
Почну з короткої історичної довідки. 12 років тому кількох до того не знайомих між собою людей об’єднала ідея повернути українству заборонений до вживання, вилучений з обігу та з бібліотек, частково знищений, а частково замкнений у радянські спецхрани академічний «Російсько-український словник» за редакцією А. Кримського й С. Єфремова (1924–1933, далі РУС).
Цей багатющий словник став стрижнем сайту r2u.org.ua та рушієм і мірилом дальшої праці гурту.
Першим кроком стало сканування РУСа — за сприяння Михайлини Коцюбинської, яка допомогла отримати доступ до паперового видання, це зробив київський книжник Валентин Кульков. Через Віктора Кубайчука та Ольгу Кочергу електронна копія віднайденого словникового скарбу дійшла до зацікавлених фахівців, зокрема долучився директор видавництва «К.І.С.» Юрій Марченко, його колега Олександр Телемко, який зробив електронний текстовий файл РУСа, та програмувальник і комп’ютерний лінгвіст Андрій Рисін.
До цього ядра гурту долучалося на різних етапах і в різних проектах чимало осіб, яких тут годі перелічити. Першим результатом співпраці став 2007 року, вебсайт r2u.org.ua, де викладено електронний варіант РУСа із повнотекстовим пошуком і можливістю завантажити текстовий pdf-файл словника.
Онлайнова версія стала можливою завдяки гранту від Наукового товариства імені Шевченка у США з Фонду ім. Івана Романюка. Абревіатура-назва сайту r2u (англ. Russian to Ukrainian, тобто з російської на українську) окреслювала його спрямування: з часом додати ще низку лексикографічних раритетів та ретельно опрацьованих високоякісних словників. Згодом постав споріднений вебсайт e2u.org.ua з низкою потужних англійсько-українських та українсько-англійських словників. Паралельно тривала робота над словником словозміни української мови (нині ВЕСУМ), який ліг в основу «Правописника» і дав поштовх створенню Браунського корпусу української мови. Всі ці проекти нині активно розвиваються.
Словниковий сайт r2u.org.ua
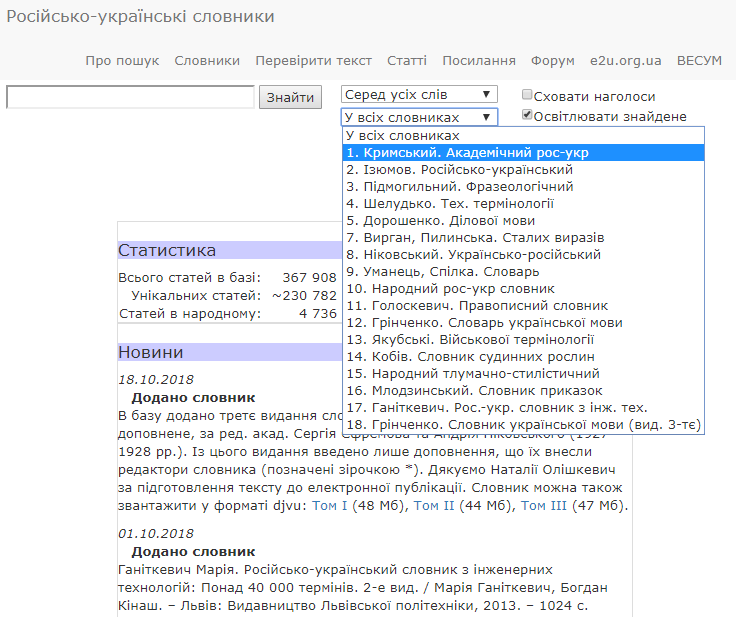
Найцінніший словник сайту — це, безумовно, РУС. Це останній лексикографічний опис української мови до початку кампанії російщення й «злиття мов» у підрадянській Україні.
РУС уклали й зредагували фахівці найвищого класу, однак вже навіть тоді вони зазнали утисків і переслідувань. Внаслідок компартійного тиску ⅕ частину надрукованого словника (над — нять) було перероблено, а четвертий том словника знищено в усіх формах, попри те, що редакційна колегія цілком підготувала його до друку.
Після цього радянська влада заборонила словник і вилучила його з продажу та бібліотек.
Нові настанови укладання словника викладено в кінці другого тому РУСа — їхня суть зводиться до того, щоб «не допуститися в цій його частині шкідливих буржуазних і націоналістичних тенденцій попередніх випусків», «подавати поширені міжнародні слова і терміни в їх інтернаціональній формі, не перекладаючи їх штучно, без потреби на українську мову». І навіть у такій частково понищеній і понівеченій формі РУС розкриває подиву гідне багатство української мови. У 1950-х роках Ю. Шевельов назвав його «найвищим авторитетом у справі норм української літературної мови».
У наш час Є.А. Карпіловська, О.Д. Кочерга та Є.В. Мейнарович так оцінюють значення РУСа: він «є не лише найґрунтовнішим натепер російсько-українським словником, а й джерелом питомої української лексики, взірцевих словотворчих моделей, мовних конструкцій та усталених висловів, зразків запозичування іншомовних слів та їх адаптування до системи української мови. Він не лише не застарів, а по глибшому вивченні напевне постане як найповніше й найдокладніше сучасне лексикографічне джерело, що його значення для дальшого розвитку української мови важко перебільшити».

Онлайнова версія з гнучким пошуковим інтерфейсом дає змогу використовувати цей словник не лише для російсько-українського перекладу, а, наприклад, для пошуку слів, близьких за значенням чи формою.
Приміром, пошук на слово блищати видасть такі синоніми: блискотіти, виблискувати, вилискувати, зоріти, горіти, ясніти, світити, сяяти; (про рівну й гладку поверхню) вилискувати, лисніти, лиснитися, лощитися; (мінливим світлом, блиском) грати, вигравати, мигтіти, жахтіти, бреніти, леліти; (коли-не-коли, місцями) блискати, поблискувати, полискувати; (загорятися й гаснути) блимати, бликати.
Пошук на *тель серед «українських слів без цитат» видає десятки слів із суфіксом -тель, зокрема таких, що їх годі знайти в сучасних словниках: воскреситель, всесотворитель, відновитель, гоїтель, землерушитель, зачатель, зловчитель, звіститель, сповіститель, вибавитель, вивіритель, миритель, світоправитель тощо.
Загалом РУС містить значний шар питомої, однак призабутої (зокрема внаслідок втручання сумнозвісних позамовних чинників) лексики, що може стати джерелом збагачування сучасної мови. Перші ґрунтовні дослідження в цьому напрямі засвідчують відродження цієї лексики. Втішає той факт, що завдяки сайту r2u та недавньому перевиданню першого тому в паперовому форматі РУС не лише повернувся до активного обігу, а й стає об’єктом докладних лінгвістичних досліджень. Дослідники навіть роблять виважені спроби реконструювати втрачений 4-й том словника.
Словники сайту r2u стають у пригоді не лише мовознавцям, вчителям і викладачам української мови, студентам, а й перекладачам не з російської мови. Річ у тім, що нерідко трапляється ситуація, коли складно дібрати влучний відповідник до англійського, французького чи іншого чужомовного слова або вислову, а словники між цими мовами й українською не подають достатньої кількості відповідників. Тоді пошук на r2u (за російським чи українським словом, або ж кількаразовий пошук за різними словами) може привести перекладача до шуканої одиниці чи підказати влучний відповідник. Наприклад, автор цих рядків постійно і з великою користю послуговувався ресурсами r2u під час перекладу автобіографії Нельсона Мандели з англійської на українську мову.
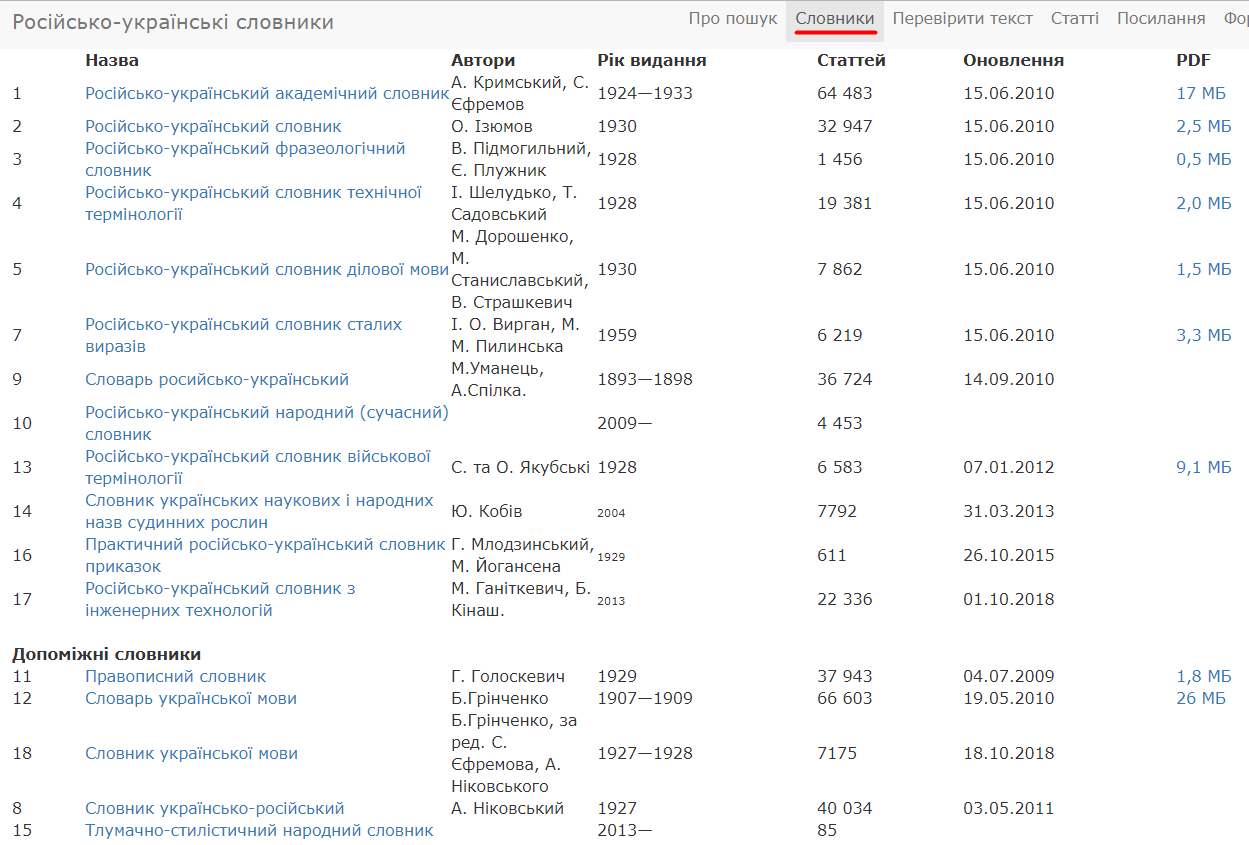
До бази сайту r2u внесено загалом 17 словників загальним обсягом 367 тис. словникових статей, із яких близько 230 тис. унікальні. Абсолютна більшість словників — російсько-українські й належать до періоду українізації. З давніших словників подано двічі вичитаний «Словарь української мови» за редакцією Бориса Грінченка та «Словарь росийсько-український» М. Уманця (М.Ф. Комарова) й А. Спілки. У базі сайту є й сучасний словник Юрія Кобіва, що містить тисячі народних назв рослин, а також «Українсько-російський словник» А. Ніковського 1927 року та «Правописний словник» Г. Голоскевича 1929 року. Своєю лексикографічною колекцією сайт завдячує, зокрема, тим, хто переводив словники з оригіналу в електронну форму, — насамперед Вікторові Кубайчуку.
Добірка на сайті таких цінних словників, як академічний РУС, «Російсько-український словник сталих виразів» І. Виргана та М. Пилинської, «Російсько-український фразеологічний словник» В. Підмогильного й Є. Плужника та «Практичний російсько-український словник приказок» Г. Млодзинського (за ред. М. Йогансена), слугує прекрасним ресурсом з української фразеології.

Переважну більшість словників користувачі можуть звантажити собі у формі текстових pdf-файлів зі сторінки «Словники», однак досвід показує, що набагато зручніше й швидше користуватися пошуком на сайті, адже він виводить результати пошуку послідовно з кожного словника в базі. До того ж, у розділі «Словники для звантаження» викладено електронні копії (зображення) кільканадцяти словників, що ними можна користуватися офлайн. Це словники української мови П. Білецького-Носенка й Д.І. Яворницького, «Стилістичний словник» І. Огієнка, «Словник чужомовних слів, виразів і приповідок» О. Скалозуба, низка термінологічних словників. Однак навіть найбільша колекція словників не може задовольнити всіх потреб користувачів. Тут на допомогу приходить форум сайту, де можна отримати мовні консультації, порадитися щодо вибору відповідника, обговорити складні питання слововжитку, запропонувати свої варіанти перекладу тощо. На основі дописів зареєстрованих користувачів форуму поповнюється сучасний «народний» російсько-український словник. Народним його названо через те, що забраклі статті й відповідники пропонують самі користувачі сайту. Після обговорення на форумі (інколи досить докладно і з посиланнями на текстові джерела) статтю в словник додає редактор. У такий спосіб мовці долучаються до лексикографічного опису гостроактуальної лексики, якої часто бракує в паперових словниках.
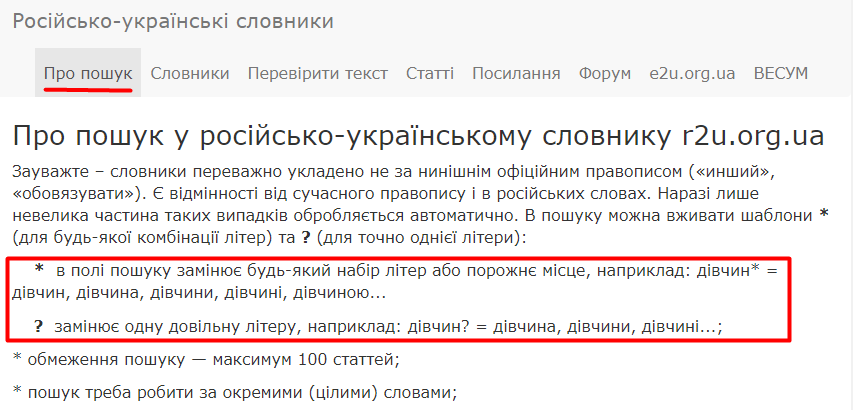
У розділі «Про пошук» описано, на що слід звертати увагу, формуючи пошукові запити на сайті. Високу гнучкість пошуку забезпечують символи заміни, що їх можна використовувати в пошукових запитах: ? замінює будь-яку одну літеру (наприклад, на запит клас? буде знайдено класу, класі тощо), а знак зірочки * замінює нуль або більше літер (клас* — клас, класу, класі, класом, класами, класний, класти, класифікація тощо).
На сайті втілено елементи інтерактивності: це не лише форум, а й можливість відсилати адміністраторам звіти про помічені помилки. Такий зворотний зв’язок дає змогу періодично очищати словники від помилок. Завдяки прискіпливому добору високоякісних словників сайт r2u належить до найпопулярніших словникових інтернет-ресурсів України, опрацьовуючи близько 1,7 млн запитів на рік із понад 76 тис. різних IP-адрес, і ці показники постійно зростають.
Словниковий вебсайт e2u.org.ua

Як вказує назва (e2u — English to Ukrainian), цей ресурс покликаний задовольнити потреби переважно в англійсько-українських словниках. На відміну від r2u, тут викладено сучасні словники.

Словникова колекція сайту складається з фундаментальних термінологічних словників, що містять великий відсоток загальномовної лексики, а також фразеологічних та загальних словників. Поданий на сайті «Англійсько-українсько-англійський словник наукової мови (фізика та споріднені науки)» О. Кочерги та Є. Мейнаровича, що містить понад 280 тис. гасел у двох частинах, — це один із найбільших термінологічних словників України.
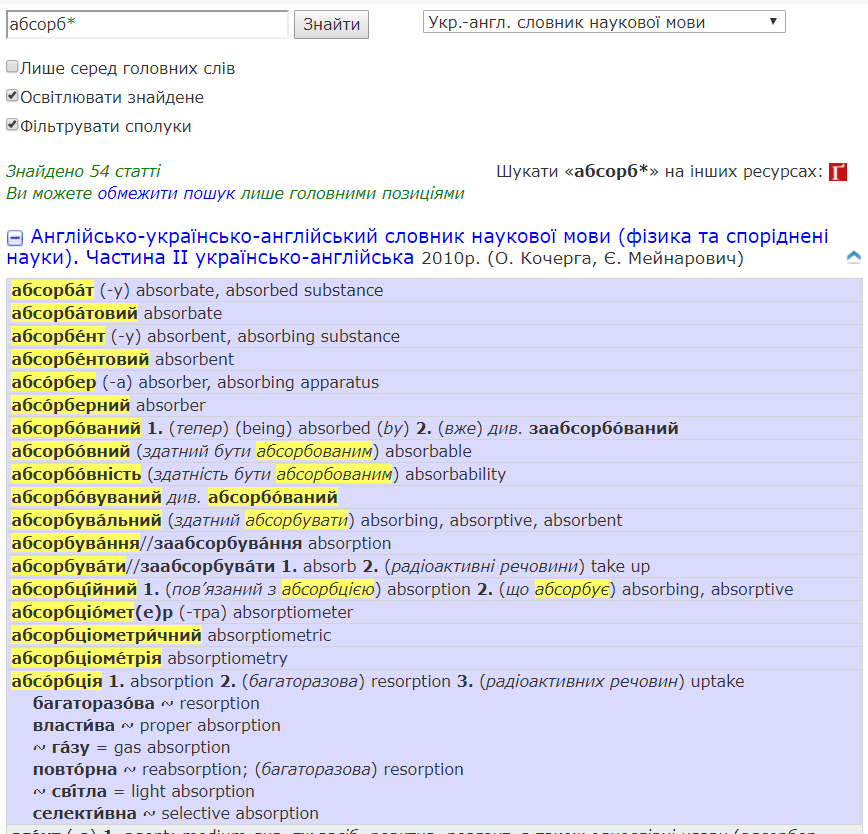
До бази сайту внесено й ґрунтовні сучасні термінологічні словники в галузі математики та інформатики, хімії, економіки, лінгвістики. Викладено також великий діаспорний українсько-англійський словник К. Андрусишина й Я. Крета на 133 тис. гасел. На основі запитів користувачів триває укладання «народного» англійсько-українського словника (понад 4 тисячі ретельно опрацьованих статей): помічаючи прогалини в наявних на сайті словниках, користувачі пропонують і обговорюють нові статті на форумі, а редактор (Андрій Рисін) укладає їх, спираючись, зокрема, на сучасні тлумачні словники англійської мови й англійсько-українські словники. Окрім того, сайт автоматично веде статистику запитів із нульовим результатом (у словниках нічого не знайдено). Найчастотніші з них вказують на те, яких статей найбільше бракує користувачам, і редактор згодом додає їх до народного словника. Поповнюється новими статтями англійсько-український фразеологічний словник (Фразлекс). Недавно додано фундаментальний енциклопедичний глосарій з хімії, «Англійсько-український словник-довідник інженерії довкілля», «Українсько-англійський словник з радіоелектроніки». Наразі словникова база сайту нараховує сумарно понад 693 тис. гасел.
Великий електронний словник української мови (ВЕСУМ)
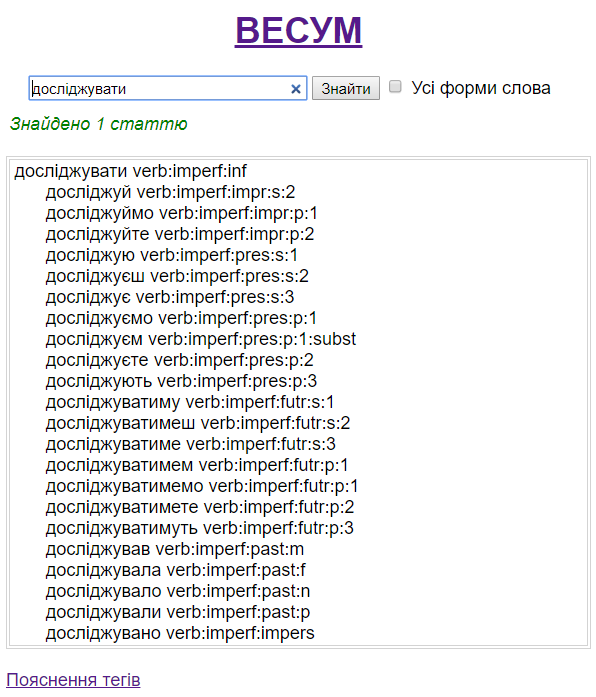
В основі багатьох засобів автоматичного опрацювання природної мови лежить словник словоформ. У мовах аналітичного типу він може мати форму списку повних словоформ, однак для мов із високим ступенем флективності, до яких належить й українська, оптимальна будова словника — це зазвичай список лем із кодами словозміни, на основі яких генеруються всі потрібні словоформи. Саме такий підхід використано у ВЕСУМі.
Починаючи від 1990-х років, ВЕСУМ пройшов довгий шлях від словника для перевіряння орфографії у відкритій операційній системі «Лінукс» до сучасного електронного словника лем, словоформ і граматичних ознак (тегів) у машиночитному форматі. З обсягом 360 тис. лем, з яких генеруються понад 4,5 млн словоформ, ВЕСУМ — найбільший словник такого типу для української мови. Усі виходові дані проекту викладено у вільному доступі онлайн. Словник використано для забезпечення роботи «Правописника», для морфологічного аналізу в Браунському українському корпусі (про це нижче) та в інших проектах із комп’ютерної лінгвістики, зокрема для побудови векторів слів. У червні 2017 р. за допомогою нового українського аналізатора на основі ВЕСУМа переіндексовано базу пошуку української Вікіпедії. Якщо раніше тут застосовували змодифікований російський аналізатор з неуникними прогалинами в пошуку, то тепер у результатах виводиться шукане слово в усіх його словоформах.
У роботі над словником гурт r2u спирався передусім на ґрунтовний «Граматичний словник української літературної мови. Словозміна» колективу авторів під керівництвом В.І. Критської та за редакцією Н.Ф. Клименко, залучаючи й інші джерела («Словники України», «Активні ресурси сучасної української номінації», «Великий тлумачний словник сучасної української мови»). Теоретичні підвалини забезпечила академічна «Теоретична морфологія української мови» І. Вихованця і К. Городенської. ВЕСУМ характеризують такі ключові особливості:
1) компактна система кодів відмінювання та тегів слів;
2) охоплення абревіатур і скорочень;
3) подання альтернативних правописних варіантів, рідковживаних слів і форм;
4) понад 49 тис. власних назв, зокрема понад 24 тис. прізвищ (українських та часто вживаних іноземних), 3 тис. імен та географічні назви, запроваджені внаслідок декомунізації;
5) подання нерекомендованих слів (активних дієприкметників, невдалих кальок тощо) та варіантів їх заміни;
6) відкритість проекту.
Словозміну у ВЕСУМі зреалізовано з використанням таких компонентів:
1) словник лем із кодами парадигм;
2) правила генерування словоформ на основі цих кодів;
3) програмова логіка генерування словоформ;
4) винятки.
Жоден словник не здатен охопити всіх можливих слів, проте електронний формат ВЕСУМа дав змогу впровадити так зване «динамічне тегування», коли засіб розпізнає певні типи слів у реченні за шаблонами замість шукати їх у списку лем. Цей підхід застосовано, зокрема, до таких класів слів:
1) деякі складні прикметники (наприклад, 125-та, австро-німецький);
2) прислівники на по (наприклад, по-чилійськи, по-чилійському);
3) складні іменники (лікар-гомеопат, місто-герой);
4) слова з частотними формантами арт-, інтернет- тощо (близько 400 формантів).
Точність розпізнавання таких типів слів (в усіх відмінкових формах) за допомогою динамічного тегування становить близько 95%. Легко бачити, що простим переліком такі слова в словнику задати важко та й навряд чи доцільно.
Приклад слова з кодом парадигми
близнюк /n20.a.p.ke.<
Код вказує на те, що близнюк — це відмінюване слово чол.р., II відміни без чергування і/о, істота, з закінченням -а в род. в. й -е в кл. в.
У файлі ВЕСУМа base.lst це слово стоїть за абеткою серед інших слів із кодами парадигм:
…..
близницький /adj
близнуватий /adj :rare
близнюк /n20.a.p.ke.<
близнюковий /adj
близнючка /n10.p2.ko.<
близня /n40.p.< :xp1 # близнюк
близня /n10 :xp2 # близнята
ВЕСУМ виконує завдання морфологічного аналізу й синтезу. Синтез передбачає генерування всіх словоформ певної леми, а аналіз полягає в лематизації (зведенні словоформи до леми) й присвоєнні цій словоформі відповідних граматичних тегів. Наприклад, словоформа розумієте лематизується до розуміти й дістає перелік граматичних тегів verb:imperf: pres:p:2, тобто дієслово, недоконаний вид, теперішній час, множина, друга особа. Відповідно, під час синтезу з леми розуміти генеруються словоформи з такими ланцюжками тегів:
розуміти verb:imperf:inf
розумій verb:imperf:impr:s:2
розуміймо verb:imperf:impr:p:1
розумійте verb:imperf:impr:p:2
розумію verb:imperf:pres:s:1
розумієш verb:imperf:pres:s:2
Отже, ВЕСУМ не лише перевіряє орфографію, граматичну правильність і стилістичну витриманість тексту, а й слугує для забезпечення повнотекстового пошуку (у Вікіпедії та на інших платформах) і є ключовим складником проектів у галузі комп’ютерної лінгвістики. Від інших таких словників він відрізняється насамперед форматом (машиночитний, вільно поширюваний), ширшим охопленням лексики (зокрема власних назв) і динамічним характером (постійно поповнюється). Для забезпечення зручного доступу до ВЕСУМа як до довідкового джерела на сайті r2u створено користувацький інтерфейс словника, який виводить на екран всю парадигму шуканого слова. Якщо ж потрібно знайти, в парадигмах яких слів трапляється певна словоформа, то її варто шукати, вибравши опцію «Усі форми слова». Наприклад, словоформу мила буде знайдено в парадигмах п’ятьох різних слів
Правописник LanguageTool

На платформі languagetool.org створено засоби перевіряння орфографії, граматики й стилю для понад 20 мов. Гурт r2u розвиває український модуль під назвою «Правописник», що нині містить понад 600 правил. Основну частину роботи в цьому напрямі виконує Андрій Рисін. Модуль спирається на чинний правопис, в його основі лежить словник ВЕСУМ на 360 тис. лем, що дає змогу перевіряти тексти різної тематики й рівня складності, а також список понад 3 тис. однослівних покручів із варіантами виправлення. Перш ніж додати правило до модуля, гурт тестує його на корпусі текстів обсягом понад 100 млн словоформ і вишліфовує на основі отриманих результатів. В основу правил перевіряння покладено принцип точного розпізнавання: правило спрацьовує лише тоді, коли можна з певністю твердити про наявність помилки в тексті. З погляду користувача це вигідно відрізняє «Правописник» від подібних засобів, що застосовують принцип широкого охоплення: правило спрацьовує в усіх місцях потенційних помилок, наприклад, щоразу на слові даний, незалежно від того, чи правильно його насправді вжито в реченні. «Правописник» перевіряє різні типи помилок: орфографічні, пунктуаційні, граматичні, стилістичні й логічні. Введений текст він автоматично розбиває на речення, речення — на лексеми (числа, пунктуаційні знаки), до кожного слова встановлює його лему (проводить лематизацію) й граматичні ознаки (наприклад, іменнику надає теги частини мови, роду, числа й відмінка). Проведений у такий спосіб морфологічний аналіз дає змогу гнучко застосовувати розроблені правила, охоплюючи ними всі словоформи потрібного слова. Коли спрацьовує одне з таких правил, засіб виводить на екран повідомлення про помилку, короткий опис та пропозиції виправлення.
Приклади до кожного типу правил:
мовні покручі: рани заживають (замість загоюються), присвоїти (замість надати) звання, грецький (замість волоський) горіх, користуватися попитом (замість мати попит), переводити (замість переказувати) гроші; граматичні помилки: згідно чого (згідно з чим), навчати чому (чого), завідувач чим (чого);
логічні помилки: 30 лютого;
орфографічні помилки: смт. (зайва крапка в скороченні), гривна (гривня);
пунктуаційні помилки: почервоніти, як рак (зайва кома), Ви мабуть знаєте (вставне слово не виділено комами);
стилістичні помилки: більш світліший (світліший), о одинадцятій (порушення правил милозвучності), виборна кампанія, виборча посада (плутання паронімів), головний пріоритет (плеоназм).

Скористатися «Правописником» можна в кілька способів: на сайтах languagetool.org/uk/ та https://r2u.org.ua/check, встановивши додаток у браузери «Фаєрфокс» та «Хром» чи в програму «ЛібреОфіс». Існують також додатки для документів Ґуґла й текстового редактора «Ворд» (у преміум-версії). Принцип роботи засобу такий: вставлений або виділений текст надсилається на сервер, обробляється (але не зберігається на ньому) й повертається користувачеві разом зі звітами про помилки. Виняток — додаток до «ЛібреОфіс» та стільнична версія, що працюють в автономному режимі. Віднедавна в додатку LanguageTool, зокрема і в українському модулі, з’явилася корисна функція: перевірка тексту в режимі реального часу. Наприклад, Ви набираєте електронного листа, й LanguageTool відразу автоматично підкреслює помилково набрані слова, наприклад,

Щоби скористатися цим функціоналом, достатньо встановити додаток LanguageTool у браузер. Він автоматично розпізнає мову (не лише українську, а й англійську, німецьку, польську тощо) й перевіряє текст.
Отже, «Правописник» представлений як:
Онлайн-сервіс на та
Додаток для LibreOffice (автономний)
Додаток для Firefox та Chrome
Додаток для Google Docs
Стільнична версія (автономна)
Додаток для Microsoft Word (преміум-версія).
У повідомленнях про деякі помилки подано гіперпосилання на онлайнові ресурси з докладнішим поясненням, наприклад, на книжку Б. Антоненка-Давидовича «Як ми говоримо». Завдяки цьому «Правописник» виконує й освітню функцію, сприяючи підвищенню мовної культури користувачів. Засіб також сигналізує користувачеві, що слово написано згідно з альтернативним правописом. Таке повідомлення з’являється, приміром, до слів проєкт, радости, діягональ тощо. Виловлює він і мішанину розкладок клавіатури, коли замість українських літер вставлено латинські — така заміна не помітна для людського ока, але збиває алгоритми машинного опрацювання мовних даних, зокрема під час пошуку.
Користувачі засобу мають змогу сформулювати власні правила й відіслати їх на розгляд. Розробники постійно поповнюють набір правил, зокрема додають важкоформалізовні правила перевіряння узгодження між словами в реченні. Завдяки доступності, гнучкості й опертю на великий, постійно поповнюваний словник «Правописник» допомагає редакторам, перекладачам, студентам і всім, хто працює з текстами, не лише позбутися багатьох помилок, а й глибше опанувати багатства української мови. До того ж, у «Правописник» легко додати новий набір правил — наприклад, коли буде затверджено новий український правопис. Тоді користувачі бачитимуть повідомлення про те, за яким правописом, новим чи вже нечинним, написано те чи те слово.
Отже, «Правописник» — це зручний електронний засіб контролю якості українських текстів, систематизації й практичного застосування мовностилістичних правил, підвищення грамотності й мовної культури. За умови масового й систематичного користування він здатен заощадити час і зусилля багатьох редакторів, коректорів й авторів текстів.
Засоби для українського NLP
У процесі створення «Правописника» LanguageTool було розроблено низку утиліт, що їх можна використовувати для завдань автоматичного опрацювання українських текстів, наприклад, токенізації, лематизації та морфологічного тегування. Ці утиліти викладено й описано в окремому репозитарії. Ними успішно опрацьовано великі масиви українських текстів: корпус ГРАК (понад 300 млн токенів у версії 4), корпус УберТекст групи lang-uk (понад 665 млн токенів).
Утиліта аналізу тексту
groovy TagText.groovy -i <input_file> -o <output_file>
Аналізує текст і записує результат у виходовий файл:
– розбиває на речення
– розбиває на лексеми
– проставляє теги для лексем
– робить зняття омонімії (наразі алгоритм розомонімізації знімає лише декілька сотень найпростіших випадків омонімії)
Основні опції:
-f - лишає тільки першу лему із першим набором граматичних тегів (цей режим не рекомендований, бо перша лема, фактично, випадкова; плануємо додати інформацію про частоти, щоб лишати тільки найчастотнішу)
-l - одна лексема на рядок (лише для виводу в txt)
-x - вивід у форматі xml
-s - створити файл статистики омонімії
-u - створити файл статистики невідомих слів
-w - створити файл частоти словоформ
-z - створити файл частоти лем
Приклад тексту, протегованого утилітою TagText:
<S>
Для[для/prep]досягнення[досягнення/
noun:inanim:n:v_naz,досягнення/
noun:inanim:n:v_rod,досягнення/
noun:inanim:n:v_zna,досягнення/
noun:inanim:p:v_naz,досягнення/
noun:inanim:p:v_zna]поставленої[поставлений/
adj:f:v_rod:&adjp:pasv:perf]мети[мета/
noun:inanim:f:v_rod,мета/
noun:inanim:p:v_naz,мета/
noun:inanim:p:v_zna]необхідна[необхідний/
adj:f:v_kly:compb,необхідний/
adj:f:v_naz:compb]тісна[тісний/
adj:f:v_kly:compb,тісний/
adj:f:v_naz:compb]співпраця[співпраця/
noun:inanim:f:v_naz]та[та/
conj:coord,та/part]взаємозв'язок[взаємозв'язок/
noun:inanim:m:v_naz,взаємозв'язок/
noun:inanim:m:v_zna]відділу[відділ/
noun:inanim:m:v_dav,відділ/
noun:inanim:m:v_mis,відділ/
noun:inanim:m:v_rod]з[з/prep]бухгалтерською[бухгалтерський/
adj:f:v_oru]службою[служба/
noun:inanim:f:v_oru]фірми[фірма/
noun:inanim:f:v_rod,фірма/
noun:inanim:p:v_naz,фірма/noun:inanim:p:v_zna],[,/
null]яка[який/
adj:f:v_naz:&pron:int:rel:def]здійснює[здійснювати/
verb:imperf:pres:s:3]функцію[функція/
noun:inanim:f:v_zna]
Утиліта розбиття тексту
groovy TokenizeText.groovy -I <input_file> -o <output_file>
Аналізує текст і записує результат у виходовий файл:
• розбиває на речення (-s)
• розбиває на токени (-w) (результати включають пунктуацію, тому всі токени розділяються вертикальними рисками)
• розбиває на слова (-u)
Утиліта лематизації тексту
groovy LemmatizeText.groovy -i <input_file> -o <output_file>
Аналізує текст і записує результат у виходовий файл:
• розбиває на токени і видає на виході леми
• залишає омоніми
Опція -f лишає тільки першу лему (в планах — лишати тільки найчастотнішу)
Приклад лематизації:
Джерело: Попри актуальність тема трудової еміграції у сприйнятті широкого загалу пов’язана з міфами та стереотипами: у багатьох немає розуміння глибинних причин і масштабів такого явища.
Результат: попри актуальність тема трудовий еміграція у сприйняття широкий загал пов'язаний з міф та стереотип: у багато немає розуміння глибинний причина і масштаб такий явище.
Окрім описаних вище основних утиліт, готові до використання й кілька допоміжних засобів.
Утиліта конвертації в текст
ExtractText.groovy [<src_dir> [<txt_dir>]] (типово: pdf/ та txt/)
Витягує тексти з різних форматів у теці <src_dir> і складає в теку <txt_dir>. Формати:
• .pdf (вимагає pdftotext)
• .djvu (вимагає djvutxt)
• .fb2 (вимагає unoconv)
• .epub (вимагає ebook-convert)
• .doc, .docx, .rtf (вимагає unoconv)
• Також відсіює файли, в яких визначено два стовпчики в теку <txt_dir>/multicol/
Утиліта очищення тексту
CleanText.groovy [<txt_dir>] {-wc <min_word_limit>} (типово: txt/)
Читає всі файли .txt й відбирає українські (напр., задано мін. к-сть українських слів, наразі 80), вивід йде в <txt_dir>/good/
Перед цим намагається виправити типові проблеми:
• поломані/мішані кодування
• мішанину латиниці та кирилиці
• нетипові апострофи (міняє на прямий — ')
• вилучає м'який дефіс (00AD)
• об'єднує перенесення слів на новий рядок (використовуючи орфографічний словник)
Утиліта оцінювання якості тексту
EvaluateText [<txt_dir>] (типово: ./)
Читає всі файли .txt в теці й генерує файли *.err.txt для кожного з описом помилок, знайдених перевіркою граматики
LanguageTool (деякі правила вимкнені)
Також генерує файл <txt_dir>/err/ratings.txt зі статистикою для кожного файлу
Отже, в основі низки засобів для завдань NLP від гурту r2u лежить електронний словник словозміни ВЕСУМ. Засоби поширюються за Загальною громадською ліцензією GNU (GPL версії 3).
Браунський корпус (англ. Brown Corpus), що його створили В. Нельсон Френсис та Генрі Кучера в Браунському університеті (США) в 1960-х роках, став взірцем для створення таких корпусів-мільйонників для англійської й інших мов. На сьогодні це корпуси малого обсягу, які, однак, важливі тим, що на їхній основі можна побудувати статистичну модель мови й натренувати програму-аналізатор, яка далі в автоматичному режимі зможе проаналізувати значно більші обсяги текстів. З цих міркувань започатковано укладання Браунського корпусу української мови (БрУК).
Наші корпусні дослідження на матеріалі «Корпусу української мови», створеного в лабораторії комп’ютерної лінгвістики КНУ ім. Тараса Шевченка під керівництвом Н.П. Дарчук, засвідчили неоціненне значення згаданого корпусу для розвитку корпусної лінгвістики в Україні й плідність застосування корпусних методів у вивченні української мови. Водночас з’явилося усвідомлення потреби мати хай і невеликий, однак збалансований, репрезентативний і докладно параметризований корпус, що був би цілком доступний у машиночитному форматі іншим користувачам. Такий корпус ми будуємо на підвалинах оригінального Браунського корпусу англійської мови з певною адаптацією до українських реалій.
В умовах падіння загального рівня текстів в Україні, публікації незредагованих результатів машинного російсько-українського перекладу, чим грішать навіть деякі великі видавництва й потужні ЗМІ, та з огляду на те, що серед мовців є прагнення до розвитку культури мовлення й орієнтації на добірну українську мову, наріжним каменем БрУКу ми поклали вимогу високої якості текстів. Натомість застосування суто дескриптивного підходу без жодного контролю якості й походження текстів може призвести до захаращення корпусу третьосортними текстами. Інші вимоги до фрагментів корпусу загалом відповідають принципам побудови первісного Браунського корпусу:
1) твори мають бути оригінальні (неперекладні), зредаговані, прозові (не більш як 50% діалогічного мовлення у фрагменті);
2) створені й опубліковані за відносно короткий проміжок часу (у нашому випадку — 2010–2019 рр.);
3) до 2 тис. слів з одного твору (у вигляді одного або більше фрагментів).
Весь обсяг текстів БрУКу (1 млн слововжитків) складається з 9 категорій у таких пропорціях: преса (25%), художня (25%), наукова (10%), науково-популярна (5%), навчальна (15%), професійно-популярна (7%), релігійна (3%) література, адміністративні документи (3%), інші інформаційні тексти (есеї, мемуари тощо, 7%). У межах кожної категорії забезпечуємо тематичне, жанрове, географічне й авторське розмаїття, щоб досягти збалансованості й репрезентативності корпусу. Корпус має бути пролематизований, проанотований і розомонімізований (знято лексичну й лексико-граматичну омонімію). Ці завдання виконуємо за допомогою описаних вище засобів, зокрема ключову роль відіграє ВЕСУМ, а «Правописник» допомагає контролювати якість текстів. Кожен фрагмент корпусу описано в стандартному переліку метаданих, до яких входять, наприклад, прізвище й ім’я автора, назва твору, місце й рік публікації тощо; в окрему зону виносимо помічені у фрагменті помилки. Наразі обсяг зібраних текстів БрУКу — понад півмільйона слововживань. Кінцева мета полягає в тому, щоб створити корпус зі знятою омонімією, що перебуватиме у вільному доступі й стане одним із важливих чинників розвитку систем автоматичного опрацювання української мови.
Підсумовуючи, зазначу, що проекти гурту r2u некомерційні, мають практичну спрямованість і динамічно розвиваються, сприяючи становленню й розвитку екосистеми української прикладної й комп’ютерної лінгвістики. Гурт r2u відкритий до різнобічної співпраці з зацікавленими фахівцями.
В основу цього матеріалу покладено презентацію на семінарі у львівському Інституті фізики конденсованих систем (7.02.2019) та статтю в журналі "Українська мова" (2017 р., №3).
21.02.2019