Спеціальне дослідження стверджує, що ChatGPT втрачає ефективність, але деякі експерти критикують його методику. У будь-якому разі, всі вважають, що OpenAI має більше відкрити архітектуру своєї моделі штучного інтелекту.

Науковці зі Стенфордського університету та Каліфорнійського університету в Берклі опублікували дослідження, яке має показати зміни ефективності GPT-4 з плином часу. Стаття підживлює поширену, але не підтверджену думку про те, що мовна модель штучного інтелекту за останні кілька місяців гірше справляється з кодуванням і композиційними завданнями. Не всіх експертів результати переконали, але всі вважають, що відсутність ясності вказує на серйознішу проблему з тим, як OpenAI здійснює релізи своїх моделей.
У препринті під назвою "Як поведінка ChatGPT змінюється з часом?", опублікованому на arXiv, Лінцзяо Чен, Матей Захарія та Джеймс Зоу поставили під сумнів стабільну продуктивність великих мовних моделей OpenAI, зокрема GPT-3.5 та GPT-4. Використовуючи доступ до API [Application Programming Interface – інтерфейс прикладної програми], вони протестували березневу та червневу версії цих моделей на таких завданнях, як розв'язування математичних задач, відповіді на делікатні питання, генерування коду та візуальні операції. Показово, що здатність GPT-4 ідентифікувати прості числа, як повідомляється, різко впала з 97,6 відсотка у березні до лише 2,4 відсотка у червні. Дивно, але GPT-3.5 за той самий період показав кращу ефективність.







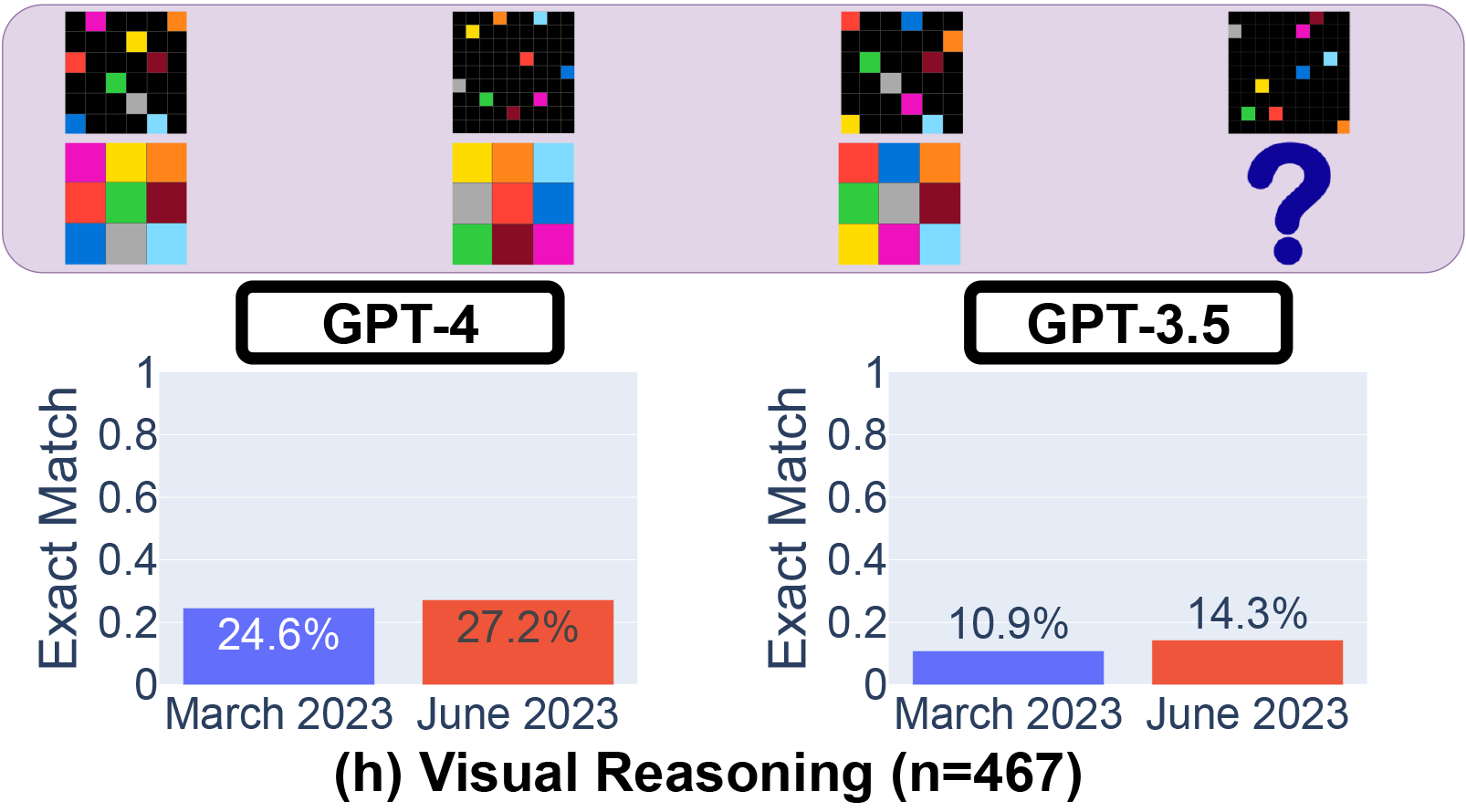
Ефективність версій GPT-4 та GPT-3.5 від березня 2023 року та червня 2023 року. Ефективність GPT-4 і GPT-3.5 може істотно змінюватися з часом, і в деяких завданнях – у гірший бік.
Це дослідження з'явилося після того, як люди почали часто скаржитися, що, за їхньою оцінкою, ефективність GPT-4 в останні кілька місяців падає. Популярні теорії щодо причин цього включають "дистиляцію" моделей OpenAI для зменшення обчислювальних навантажень у прагненні прискорити видачу результатів і економії ресурсів графічного процесора, тонке настроювання (додаткове навчання) для зменшення шкідливих результатів, які можуть мати непередбачувані наслідки, а також декілька безпідставних теорій змови, як-от: OpenAI зменшує можливості кодування GPT-4 для того, щоб більше людей платили за GitHub Copilot.
Тим часом OpenAI консеквентно заперечує будь-які заяви про зменшення ефективності GPT-4. Нещодавно віцепрезидент із виробництва OpenAI Пітер Веліндер затвітив: "Ні, ми не зробили GPT-4 тупішим. Якраз навпаки: ми робимо кожну нову версію розумнішою за попередню. Поточна гіпотеза: Коли ви використовуєте його інтенсивніше, ви починаєте помічати проблеми, яких не бачили раніше".
Хоча це нове дослідження може здатися беззаперечним доказом припущень критиків GPT-4, є такі, що радять не поспішати з висновками. Професор комп'ютерних наук з Принстонського університету Арвід Нараянан вважає, що результати дослідження не є переконливим доказом зниження продуктивності GPT-4 і потенційно узгоджуються з тонкими настроюваннями, зробленими OpenAI. Наприклад, з точки зору вимірювання можливостей генерування коду, він критикує дослідження за те, що воно оцінює швидкість написання коду, а не його коректність.
"Зміна, про яку вони повідомляють, – це те, що новіший GPT-4 додає некодовий текст на виході. Вони не оцінюють правильність коду (дивно), – твітнув він. – Вони лише перевіряють, чи є код напряму виконуваним. Тож спроба нової моделі бути кориснішою зарахована проти неї".
Дослідник штучного інтелекту Саймон Віллісон також ставить під сумнів висновки статті. "Я не вважаю їх дуже переконливими, – каже він. – Значна частина їхньої критики стосується того, чи у вихідному коді закриті маркдаунові [мова розмітки даних] лапки, чи ні". Він також знаходить інші проблеми з методологією статті. "Мені здається, що вони виставили для всього температуру 0,1 [температура GPT-4 – це налаштування, яке контролює рівень випадковості на виході, є одним з найважливіших параметрів і має значний вплив на результат, бо контролює ступінь "творчості" або різноманітності відповідей на те саме питання: вища температура згенерує більше ідей або кращу завершеність, нижча – змусить GPT-4 вибирати слова з вищою ймовірністю виникнення; температура за замовчуванням для Chat-GPT становить 0,7], – зазначає він. – Це робить результати дещо детермінованішими, але при такій температурі виконується дуже мало реальних запитів, тому я не думаю, що це нам багато говорить про приклади реального використання моделей".
Наразі, вважає Віллісон, будь-які відчутні зміни в можливостях GPT-4 пов'язані з тим, що новизна великих мовних моделей поступово зникає. Адже невдовзі після запуску GPT-4 викликав хвилю паніки щодо можливостей AGI [Artificial general intelligence – сильний штучний інтелект, який може успішно виконати будь-яку інтелектуальну задачу, виконувану людиною] і був свого часу протестований, аби побачити, чи зможе він захопити світ. Тепер, коли технологія стала більш буденною, її недоліки більше впадають в око.
"Коли вийшов GPT-4, ми ще перебували в такому стані, коли все, що могли зробити великі мовні моделі, здавалося дивовижним, – каже Віллісон. – Тепер це минуло, і люди намагаються використовувати його для реальної роботи – тому його недоліки стають очевиднішими, через що він здається менш здібним, ніж вважали спочатку".
OpenAI знає про нове дослідження і заявляє, що відстежує повідомлення про зниження ефективності GPT-4. "Команда обізнана про повідомлені регресії і вивчає їх", – затвітив Логан Кілпатрик, керівник відділу деврелу OpenAI [зв'язків компанії зі спільнотою розробників].
OpenAI є вкрай закритою
Хоча стаття Чена, Захарії та Зоу може бути неідеальною, Віллісон розуміє труднощі точного й об'єктивного вимірювання мовних моделей. Критики знову і знову вказують на все ще закритий підхід до штучного інтелекту компанії OpenAI, яка для GPT-4 не розкрила джерел навчальних матеріалів, вихідного коду, вагових коефіцієнтів нейронної мережі або навіть документів, що описують її архітектуру.
З такою моделлю закритого чорного ящика, як GPT-4, дослідники змушені спотикатися в темряві, намагаючись визначити властивості системи, яка може мати додаткові невідомі компоненти – такі як захисні фільтри або вісім "експертних" моделей, які, за недавніми чутками, працюють спільно під капотом GPT-4. До того ж, модель може змінитися в будь-який момент без попередження.
"Провайдери моделей штучного інтелекту відстають від передового досвіду традиційної програмної інфраструктури", – каже письменник і футуролог Даніель Джеффріс, який вважає, що ці провайдери повинні продовжувати довгострокову підтримку старих версій моделей при впровадженні нових, "щоб розробники програмного забезпечення могли створювати на основі надійного артефакту, а не того, який може змінитися за одну ніч без попередження".
Одним із рішень цієї нестабільності розробників і невизначеності дослідників можуть бути моделі з відкритим або доступним вихідним кодом, як-от Llama від Meta. Завдяки широко розповсюдженим файлам вагових коефіцієнтів (ядро нейромережевих даних моделі) ці моделі можуть дозволити дослідникам працювати з одними і тими ж вихідними даними і надавати повторювані з часом результати без побоювань, що компанія (наприклад, OpenAI) раптово змінить модель або відкличе доступ до неї через API.
У цьому контексті дослідниця штучного інтелекту Саша Луккіоні з компанії Hugging Face теж вважає непрозорість OpenAI проблематичною. "Будь-які результати на моделях із закритим вихідним кодом неможливо відтворити і перевірити, а отже, з наукової точки зору, ми порівнюємо єнотів і білок, – каже вона. – Це не науковці повинні постійно контролювати розгорнуті великі мовні моделі. Це справа творців моделей – надати доступ до основних моделей, принаймні для цілей аудиту".
Луккіоні наголосила на відсутності у цій галузі стандартизованих тестів, які би полегшили порівняння різних версій однієї і тієї ж моделі. Вона каже, що з кожним випуском моделі штучного інтелекту розробники повинні включати результати загальних бенчмарків [контрольне завдання для визначення порівняльних характеристик продуктивності комп'ютерної системи], таких як SuperGLUE і WikiText, а також бенчмарків на упередженість, таких як BOLD і HONEST. "Вони дійсно повинні надавати необроблені результати, а не лише метрики високого рівня, щоб ми могли бачити, де вони працюють добре і де зазнають невдачі", – каже вона.
Віллісон погоджується. "Щиро кажучи, найбільшою проблемою може бути відсутність приміток до релізу та прозорості, – каже він. – Як ми можемо створювати надійне програмне забезпечення на платформі, яка змінюється повністю незадокументованим і загадковим чином кожні кілька місяців?"

Benj Edwards
Study claims ChatGPT is losing capability, but some experts aren’t convinced
Ars Technica, 20.07.2023
12.08.2023