Найсучасніші цифрові технології дають змогу відстежувати частоту вживання окремих слів у книгах, починаючи від 1500 року. Оцифрувавши 5,2 мільйона книг, корпорація Google спільно з науковцями з Гарварду створили проект N-gram. Він започаткував цілий напрям досліджень – культуроміку, тобто дослідження розвитку мови та культури за допомогою аналізу оцифрованих текстів.
За історію людства написано мільйони книг. Зрозуміло, що прочитати навіть невеликий відсоток з них йде далеко за межі людських можливостей. Найсучасніші цифрові технології, однак, надали змогу відстежувати частоту вживання окремих слів у книгах, починаючи від 1500 року й дотепер. Оцифрувавши 5,2 мільйона книг (4% з усієї кількості створених людством), фахівці корпорації Google спільно з науковцями з Гарвардського університету 2010 року створили проект N-gram, який містить базу з понад 500 мільярдів слів англійською, французькою, німецькою, іспанською, російською та китайською мовами. Проект започаткував цілий напрям досліджень – культуроміку, суть якої в дослідженні розвитку мови та культури за допомогою аналізу оцифрованих текстів.
За допомогою Google N-gram можна, наприклад, побачити, як кількість вживань слова «жінки» у 2-й половині 1980-х рр. випередило слово «чоловіки»; як імена знаменитостей у 20 столітті «затухали» вдвічі швидше, ніж у 19-му; як технологічні терміни для широкого утвердження потребували в середньому 66 років у 1800 р. та лише 27 років – у 1880-му тощо.
Чи не найкраще Google N-gram проливає світло на еволюцію мови. Цікавим дослідженням у цій сфері є стаття А. Петерсена, Дж. Тененбаума, Ш. Хоуліна та Ю. Стенлі «Статистичні закони, що регулюють флуктуації у вживанні слів від їх народження до смерті» (Statistical Laws Governing Fluctuations in Word Use from Word Birth to Word Death). Об’єктом свого аналізу вчені зробили часовий проміжок від 1800 до 2000 р., який є надзвичайно багатий на технологічні та політичні події. Опираючись на дані Google N-gram, автори дійшли до висновку, що мова – це конкурентне середовище, в якому діють такі ж закони відбору, як у природі. Слова «борються» за виживання, й ті із них, які широко вживаються сьогодні, цілком не застраховані від забуття завтра. Прикладом, яким автори ілюструють цю думку, є англійські слова «radiogram», «roentgenogram», «Х-ray», які мають однакове значення – рентгенівський знімок. Хоча слова «radiogram» та «roentgenogram» домінували впродовж більшої частини 20 ст., під його кінець їх впевнено витіснив короткий термін «Х-ray». Діаграма нижче це наочно ілюструє:

На думку авторів, це зумовлено двома основними причинами – прагненням до стислості та використанням англійської як світової мови науки, що віддало перевагу слову саме англійського походження.
Конкуренція та витіснення застарілих слів новими значно прискорилася з появою масових ЗМІ та Інтернету. Найсучасніші культурні тренди, розтиражовані телебаченням та Інтернетом, нагадують сейсмічні поштовхи, які здатні миттєво змінювати мовний ландшафт, витісняючи «застарілі» слова більш «модними» (наприклад, blog замість log чи e-mail замість memo тощо).
Конкурентний відбір у лінгвістиці значно прискорився завдяки електронним системам перевірки тексту. Внаслідок їх застосування у текстах стало не лише менше слів із граматичними та орфографічними помилками, але й набагато менше «нестандартизованих» слів, адже комп’ютерні технології стимулюють вживання тільки тих слів, які занесені у їхні бази даних [1]. На діаграмі нижче видно поступову еволюцію коефіцієнтів «народження» (зверху) та «смерті» слів у англійській мові, англійській мові художньої літератури (English Fiction), іспанській та івриті [2]:
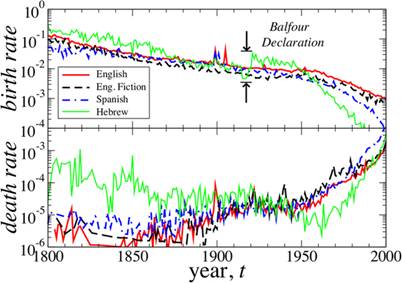
Уповільнення коефіцієнта приросту, на думку авторів, спричинене поступовим зменшенням кількості нестандартизованих слів та слів із помилками. Цікавим моментом цієї діаграми є наочна фіксація впливу політичних подій на розвиток мови. Майже п’ятиразове збільшення коефіцієнта приросту нових слів у івриті пов’язане з Декларацією Бальфура 1917 р., в якій уряд Великобританії (а згодом і лідери країн-переможниць у Першій світовій війні) висловив підтримку створенню національної держави євреїв у Палестині. Це стимулювало патріотичні почуття євреїв та їх прагнення відроджувати свою національну мову.
Окрім Декларації Бальфура, дослідження Петерсена, Тененбаума, Хоуліна та Стенлі показує вплив і інших політичних подій на розвиток мови. Показовим прикладом є війни. У країнах, які втягнені у військові конфлікти, на відміну від країн, які в них участі не беруть, значно активізуються лінгвістичні процеси. Розрахунок коефіцієнту стандартного відхилення [3] для графіків приросту нових слів у англійській мові демонструє значні коливання у роки Другої світової війни (на графіку нижче – червоний та чорний кольори). Для іспанської ж мови (зелений колір), з огляду на ізоляцію іспаномовних країн від основних вогнищ конфлікту, показник розсіювання випадкової величини від її математичного сподівання у 1939-1945 рр. є незначним:
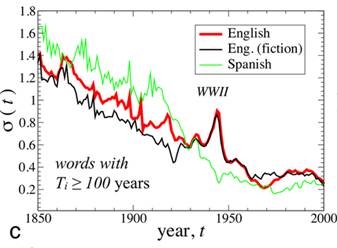
Розсіювання випадкової величини в роки конфліктів, за твердженням авторів, спостерігається не лише для англійської, але й для німецької, французької та російської мов. Це можна пояснити концентрацією суспільної свідомості навколо спільних тем, що створює сприятливе середовище для появи нових ідей.
Дослідження А. Петерсена, Дж. Тененбаума, Ш. Хоуліна та Ю. Стенлі наочно ілюструє цілий ряд закономірностей у еволюції мови. Дія статистичних законів, які регулюють процеси народження та відмирання слів, особливо прискорилася в епоху глобалізації та комп’ютерних технологій. Спостерігаються також тенденції до спрощення, «технологізації» мовлення. Стандартизовані електронні системи перевірки тексту усувають з текстів не лише орфографічні та граматичні помилки, але й «нестандартизовані» слова – архаїзми, діалектизми, неологізми тощо, – часто гублячи властиві їм найтонші семантичні та емоційні відтінки. Цілком логічно, що такі ж процеси відбуваються і в українській мові. На жаль, у Google N-gram поки ще немає оцифрованого корпусу україномовної літератури, щоби це емпірично перевірити.
- Зауважимо, що автори трактують поняття «слово» як послідовність символів, які зустрічаються у базі даних Google N-gram. Поруч із граматично правильними словами ці послідовності включають і слова з помилками, а також неологізми і випадкові комбінації.
- Дані коефіцієнти розраховуються як відношення кількості «нових» та «відмерлих» слів до усієї кількості вживаних на даний момент у мові слів.
- У статистиці – показник розсіювання значень випадкової величини відносно її математичного сподівання; позначається літерою «σ» (сигма).
Детальніше зі статтею А. Петерсена, Дж. Тененбаума, Ш. Хоуліна та Ю. Стенлі можна ознайомитися тут: http://arxiv.org/abs/1107.3707
10.01.2013