
На початку минулого року Меттью Прінс почав отримувати стурбовані дзвінки від босів великих медіакомпаній. Вони казали Прінсу, чия фірма Cloudflare забезпечує інфраструктуру безпеки приблизно для п’ятої частини інтернету, що стикаються з новою серйозною загрозою онлайн. «Я сказав: “Що, це північнокорейці?” – пригадує він. – “А вони відповіли: “Ні. Це ШІ”».
Ці керівники помітили ранні ознаки тенденції, яка відтоді стала очевидною: штучний інтелект змінює спосіб, у який люди орієнтуються в інтернеті. Користувачі ставлять запитання чат-ботам, а не звичайним пошуковикам, і отримують відповіді, а не посилання для переходу. У результаті «контент»-видавці – від новинних порталів і онлайн-форумів до довідкових ресурсів на кшталт Вікіпедії – бачать тривожне падіння трафіку.
Оскільки ШІ змінює спосіб перегляду, він змінює і саму економічну модель, що лежить в основі інтернету. Людський трафік віддавна монетизувався через онлайн-рекламу; тепер цей трафік висихає. Виробники контенту терміново шукають нові способи змусити компанії ШІ платити їм за інформацію. Якщо цього не станеться, відкритий веб може перетворитися на щось зовсім інше.
Від запуску ChatGPT наприкінці 2022 року люди охоче перейняли новий спосіб пошуку інформації онлайн. Розробник чат-бота OpenAI каже, що ним користуються близько 800 млн людей. ChatGPT є найпопулярнішим завантаженням в App Store на iPhone. Apple повідомила, що кількість звичайних пошукових запитів у її браузері Safari вперше впала у квітні, оскільки люди ставлять свої питання ШІ. Очікується, що невдовзі OpenAI запустить власний браузер.
У той час як OpenAI та інші новачки стрімко зростають, Google, який контролює близько 90% традиційного ринку пошуку в Америці, додав функції ШІ у власний пошуковик, намагаючись не відставати. Торік він почав супроводжувати деякі результати пошуку створеними ШІ «оглядами», які відтоді стали всюдисущими. У травні компанія запустила «режим ШІ» – подібну на чат-бот версію свого пошуковика. Тепер вона обіцяє, що завдяки ШІ користувачі можуть «дозволити Google ґуґлити за вас».
Та коли Google «ґуґлить замість людей», вони більше не відвідують вебсайти, з яких узята інформація. Компанія Similarweb, що вимірює трафік понад 100 млн вебдоменів, оцінює, що за рік до червня частка світового трафіку з пошукових систем знизилася приблизно на 5%. Хоча деякі категорії, як-от сайти для хобі, тримаються добре, інші серйозно постраждали. Багато з найураженіших – саме ті, які зазвичай і давали відповіді на пошукові запити. Серед медичних сайтів частка загального трафіку, що надходила з пошуковиків, впала на 10%.
Для компаній, які заробляють на рекламі чи підписках, втрачені відвідувачі означають втрату доходів. «Ми мали дуже позитивні відносини з Google протягом тривалого часу… Вони поламали угоду», – каже Ніл Воґел, голова Dotdash Meredith, що володіє такими виданнями, як People та Food & Wine. Три роки тому понад 60% їхнього трафіку приходило від Google. Тепер ця цифра становить близько 35%. «Вони крадуть наш контент, щоб конкурувати з нами», – каже Воґел. Google наполягає, що використання чужого контенту є чесним. Але відколи компанія запустила свої ШІ-«огляди», частка пошуків новин, які завершуються без переходу за посиланням, зросла, за оцінкою Similarweb, з 56% до 69%.
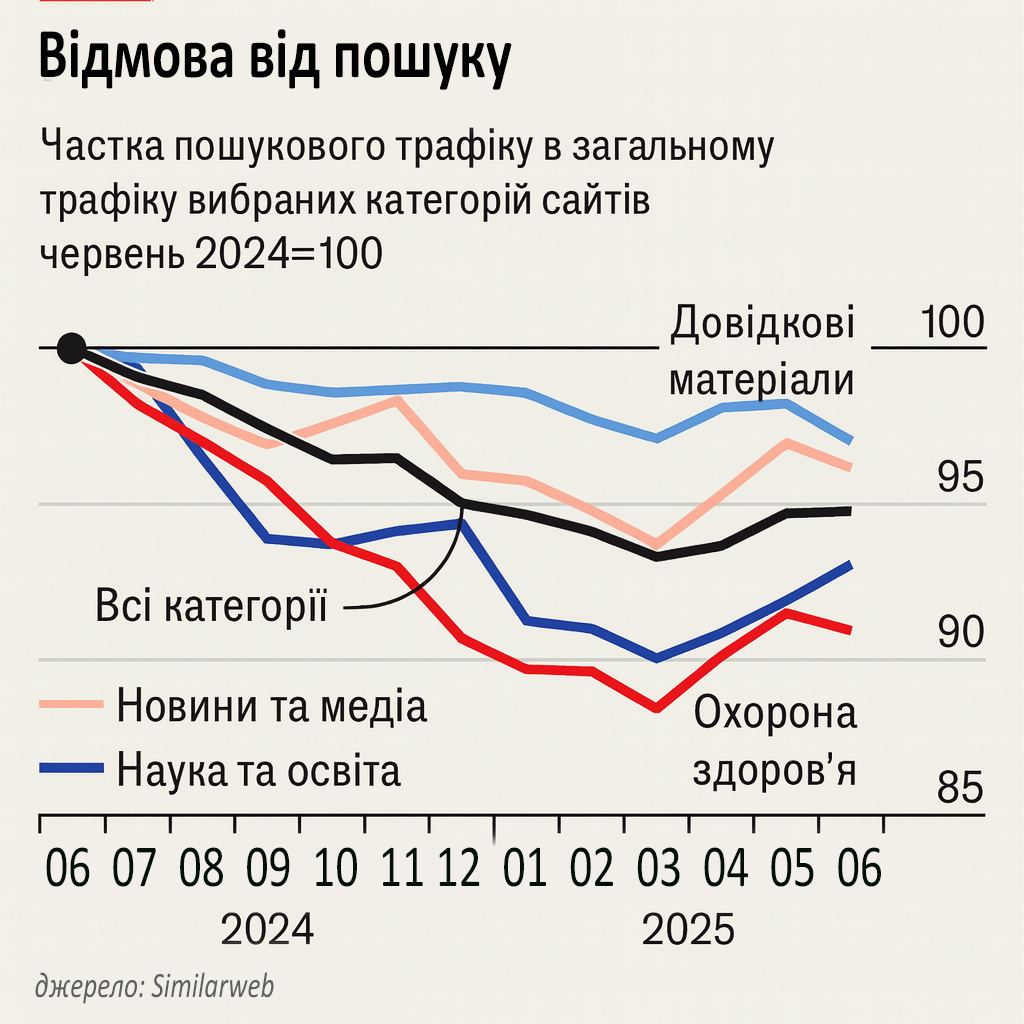
«Природа інтернету повністю змінилася», – каже Прашант Чандрасекар, генеральний директор Stack Overflow, найбільш відомого як онлайн-форум для програмістів. «ШІ фактично заглушує трафік до більшості сайтів з контентом», – каже він. З меншим потоком відвідувачів Stack Overflow бачить і менше запитань, розміщених на його форумах. Вікіпедія, яка також тримається на ентузіастах, попереджає, що створені ШІ резюме без атрибуції «перекривають шляхи, якими люди отримують доступ до сайту… і долучаються до нього».
Щоби зберегти трафік і гроші, багато великих виробників контенту винеґоціювали ліцензійні угоди з компаніями ШІ, підкріплені правовими погрозами: Роберт Томсон, генеральний директор News Corp, назвав це яко «зваблювати і позиватися». Його компанія, якій належать Wall Street Journal і New York Post серед інших видань, уклала угоду з OpenAI. Дві її дочірні компанії позиваються з Perplexity, ще одним ШІ-генератором відповідей. New York Times домовилася з Amazon, водночас позиваючись з OpenAI. Інші угоди й процеси теж тривають. (The Economist Group ще не ліцензувала наші матеріали для тренування моделей, але погодилася дозволити Google використовувати окремі статті для однієї зі своїх послуг ШІ.)
Та в цього підходу є межі. По-перше, судді наразі схиляються на бік компаній ШІ: минулого місяця дві різні справи про авторські права в Каліфорнії було вирішено на користь відповідачів – Meta та Anthropic, які аргументували, що тренування їхніх моделей на чужому контенті становить «чесне використання». Дональд Трамп, схоже, підтримує аргумент Кремнієвої долини, що їй слід дозволити розвивати технології майбутнього раніше, ніж це зробить Китай. Він звільнив очільницю Офісу авторського права США після того, як вона заявила, що тренування ШІ на матеріалах із захистом авторського права не завжди є законним.
Компанії ШІ більше схильні платити за постійний доступ до інформації, ніж за дані для тренування. Але укладені на нині угоди навряд чи є блискучими. Онлайн-форум Reddit ліцензував свій контент для Google, кажуть, за $60 млн на рік. Проте його ринкова вартість впала більш ніж вдвічі після того, як в лютому компанія повідомила про повільніше зростання користувачів, ніж очікувалося, через проблеми з пошуковим трафіком. (Відтоді зростання відновилося, а ціна акцій частково повернула втрачені позиції.)
Заплутані у павутині
Однак ще більшою проблемою є те, що більшість із сотень мільйонів доменів в інтернеті занадто малі, щоб або зваблювати, або судитися з техногігантами. Їхній контент у сукупності може бути життєво важливим для компаній зі ШІ, але кожен окремий сайт є неістотним. Навіть якби вони змогли об’єднатися для колективних переговорів, антимонопольне законодавство це б заборонило. Вони би могли блокувати краулінґ (сканування інформації) ШІ, і деякі так і роблять. Але це означає цілковиту відсутність пошукової видимості.
Постачальники програмного забезпечення можуть допомогти. Усі нові клієнти Cloudflare тепер отримуватимуть запитання, чи хочуть вони дозволити ботам компаній зі ШІ збирати дані з їхнього сайту – і з якою метою. Масштаб Cloudflare дає йому більше шансів, ніж більшості інших, запровадити щось на кшталт колективної відповіді від сайтів із контентом, які прагнуть змусити компанії ШІ платити. Нині він тестує систему pay-as-you-crawl (плати за краулінґ), яка дозволила б сайтам брати з ботів «вхідний квиток». «Ми повинні встановити правила гри», – каже Прінс, додаючи, що його бажаний результат – це «світ, де люди отримують контент безкоштовно, а боти платять за нього купу грошей».
Альтернативу пропонує Tollbit, який називає себе «пейволом для ботів». Він дозволяє сайтам із контентом брати з пошукових роботів ШІ різні тарифи: наприклад, журнал може брати більше за нові матеріали, ніж за старі. У першому кварталі цього року Tollbit обробив 15 млн таких мікротранзакцій для двох тисяч продуцентів контенту, серед яких Associated Press та Newsweek. Тошіт Паніґрагі, його генеральний директор, зазначає, що при тому, як традиційні пошукові системи стимулюють одноманітний контент («О котрій починається Супербоул?», наприклад), платний доступ стимулює унікальність. Одні з найвищих ставок за краулінґ виставляє місцева газета.
Ще одну модель пропонує ProRata, стартап, який очолює Білл Ґросс, піонер 1990-х років у сфері онлайн-реклами pay-as-you-click (плати за клік), що відтоді стала рушієм значної частини інтернету. Він пропонує, щоб гроші від реклами, розміщеної поруч із відповідями, створеними ШІ, перерозподілялися між сайтами пропорційно до того, наскільки їхній контент зробив внесок у відповідь. ProRata має власний генератор відповідей – Gist.ai, який ділиться рекламними доходами з понад 500 партнерами, серед яких Financial Times та The Atlantic. Поки що він радше приклад, ніж серйозна загроза для Google: пан Ґросс каже, що його головна мета – «показати чесну бізнес-модель, яку з часом скопіюють інші».
Виробники контенту також переосмислюють свої бізнес-моделі. «Майбутнє інтернету полягає не лише в трафіку», – каже Чандрасекар, який розбудував орієнтований на корпоративний сектор підписний продукт [для формування і зберігання внутрішньої бази знань] Stack Overflow під назвою Stack Internal. Новинні видавці планують сценарій «нульового Google» з використанням розсилок та застосунків, щоб дістатися до клієнтів, які більше не приходять через пошук, а також переводять контент на передплату чи у формат подій у реальному часі. Dotdash Meredith каже, що змогла наростити загальний трафік попри падіння переходів із Google. Аудіо та відео також виявляються юридично й технічно складнішими для генераторів відповідей у порівнянні з текстом. Сайт, на який генератори відповідей спрямовують пошуковий трафік найчастіше й з великим відривом, за даними Similarweb, – це YouTube.
Не всі вважають, що веб занепадає – навпаки, кажуть, що він перебуває «в неймовірно експансивному моменті», стверджує Роббі Стайн із Google. Оскільки ШІ спрощує створення контенту, кількість сайтів зростає: за даними ботів Google, інтернет за останні два роки розширився на 45%. Пошук на основі ШІ дозволяє людям ставити питання новими способами – наприклад, сфотографувати свою книжкову полицю й попросити порадити, що почитати далі, – що може збільшити трафік. За допомогою ШІ-запитів «прочитуються» більше сайтів, ніж будь-коли, хай і не людськими очима. Генератор відповідей може проглянути сотні сторінок, щоб дати відповідь, використовуючи значно ширший діапазон джерел, ніж звичайні люди-читачі.
Стосовно думки, що Google тепер поширює менше людського трафіку, ніж раніше, Стайн каже, що компанія не зафіксувала драматичного падіння кількості вихідних кліків, хоча й відмовляється оприлюднювати саму цифру. Існують й інші причини, не тільки ШІ, чому люди можуть рідше відвідувати сайти. Можливо, вони гортають соціальні мережі. Можливо, слухають подкасти.
Смерть вебу вже пророкували раніше – спершу від соціальних мереж, потім застосунків, – але цього не сталося. Та станом на нині ШІ може становити для нього найбільшу загрозу. Якщо веб має зберегтися у формі, близькій до теперішньої, сайтам доведеться шукати нові способи отримувати оплату. «Без сумніву, люди віддають перевагу пошуку на основі ШІ, – каже Ґросс. – І щоб інтернет вижив, щоб вижила демократія, щоб вижили творці контенту, пошук на основі ШІ має ділитися доходами з творцями».
AI is killing the web. Can anything save it?
The Economist, 14.07.2025
25.09.2025