Для опанування рідною мовою люди потребують не більше пам’яті, ніж має дискета, вирахували вчені. Згідно з даними, англомовний дорослий в середньому потребує 12,5 мільйона бітів для інформації, що дає йому змогу розмовляти рідною мовою та її розуміти. Це відповідає приблизно 1,5 мегабайтам даних. Тож в перші 18 років життя мозок запам'ятовує між 120 і 2 000 бітів щодня, виявили науковці.

Зображення: wavebreakmedia/ thinkstock.
Попри неймовірний прогрес комп’ютерної техніки та штучного інтелекту, наш мозок все ще залишається ефективнішим та продуктивнішим, ніж всяка інша мисленнєва машина. Він опрацьовує одночасно безліч подразників і дає нам змогу мислити інновативно й абстрактно, вдаватися до комплексної соціальної поведінки та комунікувати. Існують комп’ютерні системи, що розуміють розмовну мову і навіть можуть зчитати мовну інформацію з мозкових хвиль людини. Однак, порівняно з людським мозком, вони ще пасуть задніх.
Виникає запитання: скільки бітів та байтів потребує наш мозок, щоб оволодіти рідною мовою та її розуміти? Чи взагалі можливо перевести у кількісні показники здатність розмовляти та знання мови, властиве людям?
Саме цими питаннями задалися Френціс Моліка (Francis Mollica) з Рочестерського університету та Стівен Пянтадоші (Steven Piantadosi)з Каліфорнійського університету в Берклі. «Дотепер залишається суперечливим, чи обсяг знань, необхідний для опанування людської мови, – мінімальний чи, навпаки, неосяжний?» – пояснюють вчені. Для свого дослідження вони навмисно обрали радше узагальнений підхід, що дав змогу дійти висновків про потрібну для мовного оволодіння кількість даних і не ґрунтувався на жодній з відомих теорій.
«Ми не беремо до уваги, як відбувається вивчення мови, а зосередилися на питанні, скільки інформації потрібно запам’ятати тим, хто вчиться і не має жодних попередніх знань про мову», – наголосили вчені.
Аби оцінити кількість даних, науковці почали з найменшої одиниці мови – звуків та фонем. «Наші фонетичні знання дають змогу відфільтровувати та ідентифікувати важливі для мови звуки в мовних сигналах», – пояснили вони. Згідно з підрахунками, в англійській мові існує приблизно 50 різних фонем – і кожна з них як інформація охоплює приблизно 15 бітів. Тобто фонеми потребують 750 бітів пам’яті.
Наступним кроком було оцінити слова – складніші елементи мови. «Дослідження, які аналізували, скільки слів дитина вивчає, засвоюючи мову, вказують на цифру, що коливається від 20 000 до 80 000», – кажуть Моліка та Пянтадосі. Для свого дослідження вони виходити з середнього показника – близько 40 000 слів для типового молодого дорослого.
З допомогою бази даних та лінгвістичної моделі науковці визначили: щоб засвоїти фонетичну послідовність в слові, потрібно в середньому 10 бітів пам’яті. Помноживши цю цифру на кількість слів (близько 40 000), вчені з’ясували: лексичне знання фонетичної послідовності потребує приблизно 400 000 бітів пам’яті.
Суттєво складніше було визначити, яку кількість даних потребують люди, аби вивчити значення слова – тобто для так званої лексичної семантики. «Проблема полягає в тому, що дотепер немає жодної загально прийнятої теорії про семантичний зміст або обсяг», – пояснили вчені. Тож вони обійшлися узагальненими даними, які визначають ймовірний простір словесного значень як просторову величину. Що більше вимірів має цей простір, то більше даних необхідно, аби ідентифікувати конкретне значення слова.
«Коли семантичний простір одновимірний, достатньо від 0,5 до двох бітів пам’яті на слово, – сказали вчені. – Якщо він має 100 вимірів, лексична семантика потребує 50–200 бітів на кожне слово». У своїх підрахунках учені визначили середній показник і з’ясували, що для того, аби обрати коректне з можливих значень, потрібно приблизно 550 000 бітів.
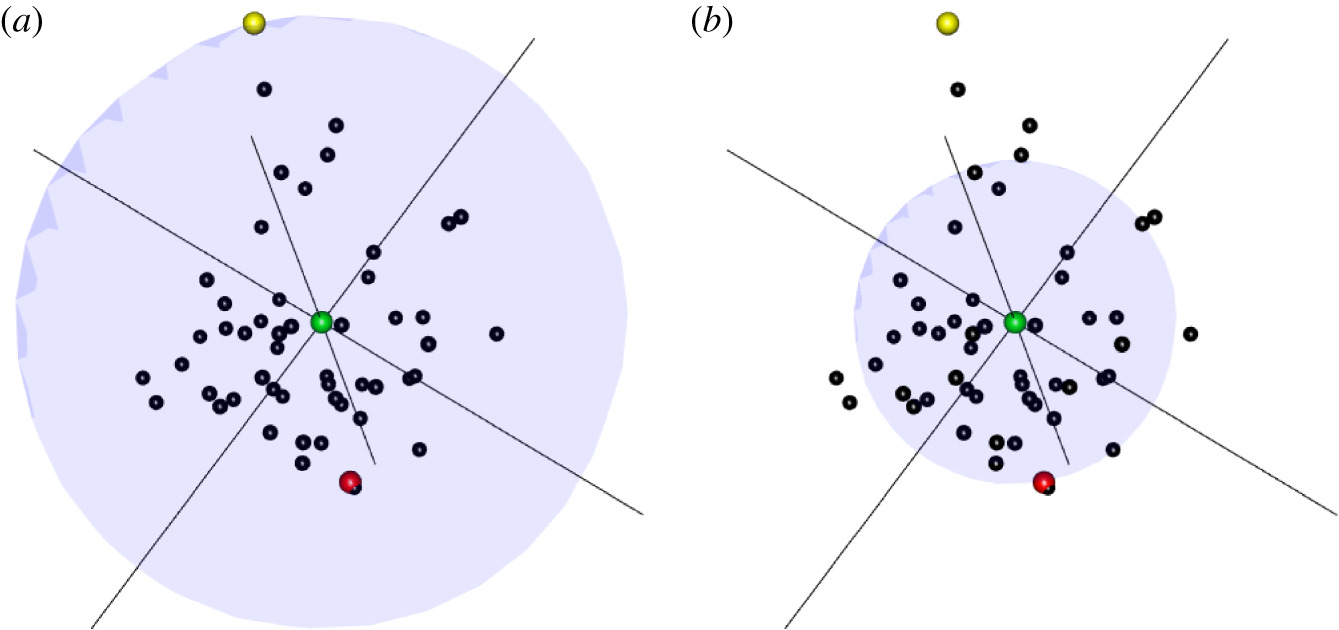
Затінені сфери представляють невизначеність в семантичному просторі, зосередженому навколо певного слова (зелене).
(a) невизначеність щодо найдальшого зв'язку слова у семантичному просторі (жовте), R.
(b) невизначеність щодо N-го сусіда слова (червоне), r.
Зменшення невизначеності від R до r відображає обсяг семантичної інформації, що передається зеленим словом.
Додатково Моліко та Пянтадоші визначили інформаційні затрати на частоту слів і синтаксис.
На підставі всіх підрахунків науковці вивели загальну суму: «За найкращими нашими оцінками, доросла англомовна людина потребує 12,5 мільйона бітів пам’яті, щоб опанувати рідну мову – більшу частину цього обсягу займає лексична семантика», – розповіли вчені.
Отримані цифри відповідають 1,5 мегабайтам. «Може, й несподівано, але, перетворивши це на цифрову пам'ять, стане видно, що наші мовні знання майже в повному обсязі можуть поміститися на дискеті».
Аби зібрати необхідні дані для вивчення мови, впродовж перших 18 років життя людина повинна зберігати та запам’ятовувати в середньому 1 000 – 2 000 бітів інформації щодня, тобто отаку приблизно послідовність:
0 1 1 0 1 0 0 0 0 1 1 0 1 0 0 1 0 1 1 0 0 1 0 0 0 1 1 0 0 1 0 0 0 1 1 0 0 1 0 1 0 1 1 0 1 1 1 0 0 1 1 0 0 0 0 1 0 1 1 0 0 0 1 1 0 1 1 0 0 0 1 1 0 1 1 0 1 1 1 1 0 1 1 1 0 0 1 0 0 1 1 0 0 1 0 0 0 1 1 0 1 0 0 1 0 1 1 0 1 1 1 1 0 1 1 0 1 1 1 0 0 1 1 0 1 0 0 0 0 1 1 0 1 0 0 1 0 1 1 0 0 1 0 0 0 1 1 0 0 1 0 0 0 1 1 0 0 1 0 1 0 1 1 0 1 1 1 0 0 1 1 0 0 0 0 1 0 1 1 0 0 0 1 1 0 1 1 0 0 0 1 1 0 1 1 0 1 1 1 1 0 1 1 1 0 0 1 0 0 1 1 0 0 1 0 0 0 1 1 0 1 0 0 1 0 1 1 0 1 1 1 1 0 1 1 0 1 1 1 0 0 1 1 0 1 0 0 0 0 1 1 0 1 0 0 1 0 1 1 0 0 1 0 0 0 1 1 0 0 1 0 0 0 1 1 0 0 1 0 1 0 1 1 0 1 1 1 0 0 1 1 0 0 0 0 1 0 1 1 0 0 0 1 1 0 1 1 0 0 0 1 1 0 1 1 0 1 1 1 1 0 1 1 1 0 0 1 0 0 1 1 0 0 1 0 0 0 1 1 0 1 0 0 1 0 1 1 0 1 1 1 1 0 1 1 0 1 1 1 0 0 1 1 0 1 0 0 0 0 1 1 0 1 0 0 1 0 1 1 0 0 1 0 0 0 1 1 0 0 1 0 0 0 1 1 0 0 1 0 1 0 1 1 0 1 1 1 0 0 1 1 0 0 0 0 1 0 1 1 0 0 0 1 1 0 1 1 0 0 0 1 1 0 1 1 0 1 1 1 1 0 1 1 1 0 0 1 0 0 1 1 0 0 1 0 0 0 1 1 0 1 0 0 1 0 1 1 0 1 1 1 1 0 1 1 0 1 1 1 0 0 1 1 0 1 0 0 0 0 1 1 0 1 0 0 1 0 1 1 0 0 1 0 0 0 1 1 0 0 1 0 0 0 1 1 0 0 1 0 1 0 1 1 0 1 1 1 0 0 1 1 0 0 0 0 1 0 1 1 0 0 0 1 1 0 1 1 0 0 0 1 1 0 1 1 0 1 1 1 1 0 1 1 1 0 0 1 0 0 1 1 0 0 1 0 0 0 1 1 0 1 0 0 1 0 1 1 0 1 1 1 1 0 1 1 0 1 1 1 0 0 1 1 0 1 0 0 0 0 1 1 0 1 0 0 1 0 1 1 0 0 1 0 0 0 1 1 0 0 1 0 0 0 1 1 0 0 1 0 1 0 1 1 0 1 1 1 0 0 1 1 0 0 0 0 1 0 1 1 0 0 0 1 1 0 1 1 0 0 0 1 1 0 1 1 0 1 1 1 1 0 1 1 1 0 0 1 0 0 1 1 0 0 1 0 0 0 1 1 0 1 0 0 1 0 1 1 0 1 1 1 1 0 1 1 0 1 1 1 0 0 1 1 0 1 0 0 0 0 1 1 0 1 0 0 1 0 1 1 0 0 1 0 0 0 1 1 0 0 1 0 0 0 1 1 0 0 1 0 1 0 1 1 0 1 1 1 0 0 1 1 0 0 0 0 1 0 1 1 0 0 0 1 1 0 1 1 0 0 0 1 1 0 1 1 0 1 1 1 1 0 1 1 1 0 0 1 0 0 1 1 0 0 1 0 0 0 1 1 0 1 0 0 1 0 1 1 0 1 1 1 1 0 1 1 0 1 1 1 0 0 1 1 0 1 0 0 0 0 1 1 0 1 0 0 1 0 1 1 0 0 1 0 0 0 1 1 0 0 1 0 0 0 1 1 0 0 1 0 1 0 1 1 0 1 1 1 0 0 1 1 0 0 0 0 1 0 1 1 0 0 0 1 1 0 1 1 0 0 0 1 1 0 1 1 0 1 1 1 1 0 1 1 1 0 0 1 0 0 1 1 0 0 1 0 0 0 1 1 0 1 0 0 1 0 1 1 0 1 1 1 1 0 1 1 0 1 1 1 0 0 1 1 0 1 0 0 0 0 1 1 0 1 0 0 1 0 1 1 0 0 1 0 0 0 1 1 0 0 1 0 0 0 1 1 0 0 1 0 1 0 1 1 0 1 1 1 0 0 1 1 0 0 0 0 1 0 1 1 0 0 0 1 1 0 1 1 0 0 0 1 1 0 1 1 0 1 1 1 1 0 1 1 1 0 0 1 0 0 1 1 0 0 1 0 0 0 1 1 0 1 0 0 1 0 1 1 0 1 1 1 1 0 1 1 0 1 1 1 0 0 1 1 0 1 0 0 0 0 1 1 0 1 0 0 1 0 1 1 0 0 1 0 0 0 1 1 0 0 1 0 0 0 1 1 0 0 1 0 1 0 1 1 0 1 1 1 0 0 1 1 0 0 0 0 1 0 1 1 0 0 0 1 1 0 1 1 0 0 0 1 1 0 1 1 0 1 1 1 1 0 1 1 1 0 0 1 0 0 1 1 0 0 1 0 0 0 1 1 0 1 0 0 1 0 1 1 0 1 1 1 1 0 1 1 0 1 1 1 0 0 1 1 0 1 0 0 0 0 1 1 0 1 0 0 1 0 1 1 0 0 1 0 0 0 1 1 0 0 1 0 0 0 1 1 0 0 1 0 1 0 1 1 0 1 1 1 0 0 1 1 0 0 0 0 1 0 1 1 0 0 0 1 1 0 1 1 0 0 0 1 1 0 1 1 0 1 1 1 1 0 1 1 1 0 0 1 0 0 1 1 0 0 1 0 0 0 1 1 0 1 0 0 1 0 1
«Наше дослідження перше, яке перевело в цифри ту кількість інформації, яку потрібно вивчити, щоб опанувати мову, – сказав Пянтадоші. – Воно засвідчує, що діти та підлітки – прекрасні учні, бо для того, щоб вивчити мову, вони зберігають понад тисячу бітів інформації щодня».
Однак науковці зазначають: їхні результати отримані в процесі грубого узагальнення, тобто їх можна було б назвати розрахунками «back-of-the-envelope» (груба оцінка, "розрахунок на обгортці"). Тим не менше, вони здаються цілком придатними для того, щоб вказати на приблизні величини.
Дивовижно, зазначають автори, що ці півтора мегабайти дозволяють оперувати семантичними комбінаціями, потенційне число яких можна оцінити в 10²¹⁰, що перевищує число атомів у Всесвіті (10⁸⁰). Результати показують, підсумовують дослідники, що коли якесь знання мови є дійсно вродженим, воно радше допоможе вирішити величезну проблему вивчення лексичної семантики, а не, скажімо, синтаксу, що вимагає на порядки менше інформації.
Nadja Podbregar
Unsere Sprache braucht 12,5 Millionen Bits
Scinexx, 28.03.2019
Francis Mollica, Steven T. Piantadosi
Humans store about 1.5 megabytes of information during language acquisition
Royal Society Open Science, 27.03.2019
Зреферувала С. К.