
Питання спорідненості мов, а особливо слов'янських, давно вже стало – а, може, і було завше – ідеологічним. А у випадку мов, які прийнято називати східнослов'янськими, воно, на жаль, є навіть політичним – а тепер (і тут оце "на жаль" недоречно м'яке) ще й смертоносним. Зрештою, про гостроту проблеми свідчить навіть цей початок, здавалобись, специфічно наукової розвідки, – початок, який цілковито випадає з конвенційної структури наукового – ба, навіть новинного¹ – тексту.

Генетичні відношення між мовами (а точніше, між лектами, тобто між мовами, діалектами чи говірками) вивчає генеалогічна лінгвістика, розкриваючи діахронічні траєкторії окремих мовних еволюційних історій та встановлюючи їх генеалогічну класифікацію на основі ступеня генетичної спорідненості² (даючи таке визначення, Матей Шеклі, зокрема, застерігає, що в цьому сенсі не можна плутати соціолінгвістичний термін літературна/стандартна мова з терміном генеалогічної лінгвістики – з мовою, якою розмовляють на певній території³).
З кінця XIX століття, з часу, коли процес виникнення мов почали розуміти як розвиток розгалужень дерева (Stammbaumtheorie⁴), вважається, що основним інструментом генеалогічної лінгвістики є історична фонологія, тобто доказом спорідненості лектів є спільні інновації, які відділили нову гілку від стовбура прамови⁵. Теорія хвиль (Wellentheorie⁶), що була заявлена як альтернатива до теорії дерева, фактично доповнювала її механізмом поширення інновацій: від одного діалекту до суміжного, мовно близького в діалектному континуумі, а цей суміжний діалект, інтерналізувавши інновацію, передає її наступному суміжному і т. д. Міграції частини населення на великі відстані призводили до різкого відгалуження його мови від материнської, а поступове розширення території проживання мовної групи вело до хвильового механізму щораз дальшого відокремлення мов діалектів на протилежних периферіях мовного ареалу⁷.
Юрій Шевельов же, підсумовуючи своє фундаментальне дослідження фонологічної еволюції праслов'янської мови⁸, фактично запропонував концепцію мережевого розвитку мов, в якій основну роль відіграють діалектні групи: "Ізоглоси п'ятого-десятого століть не виявляють жодної закономірності і майже не утворюють стабільних груп мов чи діалектів. Вони накладаються і перетинаються одна з одною в позірному безладі, ніби відображаючи неспокійну історію слов'янської мови того часу. Деякі ізоглоси перетинають те, що з сучасної точки зору є мовами, об'єднуючи їхні частини з іншими мовами [...] Розпад праслов'янської мови не був схожий на ріст дерева, яке спочатку випустило три великі гілки (східно-, західно- та південнослов'янські), з яких згодом проросли менші гілочки (окремі слов'янські мови, як ми їх знаємо). Цю дезінтеграцію також не можна осягнути за допомогою традиційної метафори хвиль, що поширюються одна за одною. Якщо метафора є доречною, то найкраще підійде образ хмар у небі в грозовий день, з їхніми постійними змінами форми, наростанням, накладанням, злиттям, роз'єднанням і здатністю миттєво зникати. [...] Лінгвістично, південноросійські та північноукраїнські діалекти могли б стати білоруськими, східнословацькі – польськими, кайкські діалекти сербохорватської – словенської, а західноболгарські – сербохорватськими, або тимокські діалекти сербохорватської – болгарськими"⁹.
Свою ідею про вирішальну роль діалектів у процесі формування мов Шевельов окреслив ще раніше у "Проблемах формування білоруської мови", а потім в "Історичній фонології української мови" він на конкретному прикладі взірцево показав, як при реконструкції історичного розвитку мови необхідно враховувати еволюцію діалектів¹⁰. Після Шевельова цей підхід розвинув (зокрема, але, як на мене, найпереконливіше) його – в певному сенсі – учень¹¹ Геннінґ Андерсен, формалізувавши метафору Шевельова про хмари концепцією різних швидкостей інновацій, діалектні ареали яких перекриваються, а їх комбінація може в результаті призвести до отого "позірного безладу" ізоглос¹².
До середини минулого століття фонологічні підходи були фактично єдиною надійною методикою реконструкції траєкторії еволюції мов. Були спроби для оцінки спорідненості мов застосувати кількісні критерії¹³, однак справа впиралась не тільки у необхідність відсіву випадкових збігів, а й у нерозв’язану проблему зважування релевантності кожного окремого показника.
Проривною стала ідея Моріса Сводеша (точніше її формалізація) про те, що в усіх мовах існує пласт базової лексики, яка передає універсальні поняття, а її список є однаковим для всіх мов, тобто не залежить від культури носіїв мови, і що заміна слів у цьому списку відбувається з найнижчою і постійною ймовірністю. Отож, виходячи з цієї ідеї, він запропонував список понять (спершу 215 слів, пізніше скорочений до 100 слів), які є універсальними і культурно нейтральними – наприклад, рука, вода, сонце, їсти, спати. Такі слова мали би слугувати своєрідними "лінгвістичними генами": наявність у двох порівнюваних лектах когнатів (слова, які мають спільне походження), які мають спільний етимон (тобто слова хоч різні за звучанням, але які етимологічно походять від спільного предка) і позначають те саме універсальне поняття, відображають глибинну генеалогічну спорідненість мов. А кількість таких слів зі спільним значенням і спільним етимоном у фіксованому списку спеціально відібраних понять відображає рівень цієї спорідненості¹⁴. Ідея про постійну ймовірність, на основі якої Сводеш та його послідовники розвинули глоттохронологію (вивченням хронологічних взаємозв'язків між мовами), використовуючи лексикостатистику для визначення приблизного часу розділення пари споріднених мов (за аналогією датування за періодом піврозпаду вуглецю ¹⁴С), не знайшла підтвердження у всіх мовах, але від неї не відмовилися, пропонуючи моделі зміни цієї швидкості в часі та для різних частин базового списку.
Якщо порівнювати більше двох лектів, то отримаємо матрицю лексичних відстаней між ними (до недавнього часу можна було сміливо казати "між мовами" – рівня діалекту такі дослідження не сягали). А маючи матрицю, можна різними математичними алгоритмами вибудувати ієрархічну кластеризацію, що буде відображати дерево еволюції мов – від прамови до сучасних мов.
Для слов'янських мов було побудовано з десяток таких генеалогій; ґрунтовний критичний огляд цих спроб подано у відносно свіжій статті А.Касьяна "Лексикостатистика"¹⁵ в "Енциклопедії слов'янських мов та лінгвістики"¹⁶: критика в основному стосується якості підбору ("garbage in, garbage out") різномовних слов'янських відповідників англійського списку Сводеша традиційних методик (проблема синонімів) та деяких аспектів нових математично абстрактніших спроб генеалогічної класифікації¹⁷. А.Касьян відзначив, що на даний час найадекватнішу глоттохронологічну схему запропоновано у публікації групи 75 авторів на чолі з А.Курашкевич (білоруської за походженням генетика з Тартуського університету)¹⁸ фундаментального дослідження 2015 року про генетичну спадщину балто-слов'яномовних популяцій, де, власне, сам А.Касьян (разом з А.Дибо) був автором лексикостатистичної частини проєкту моделі.
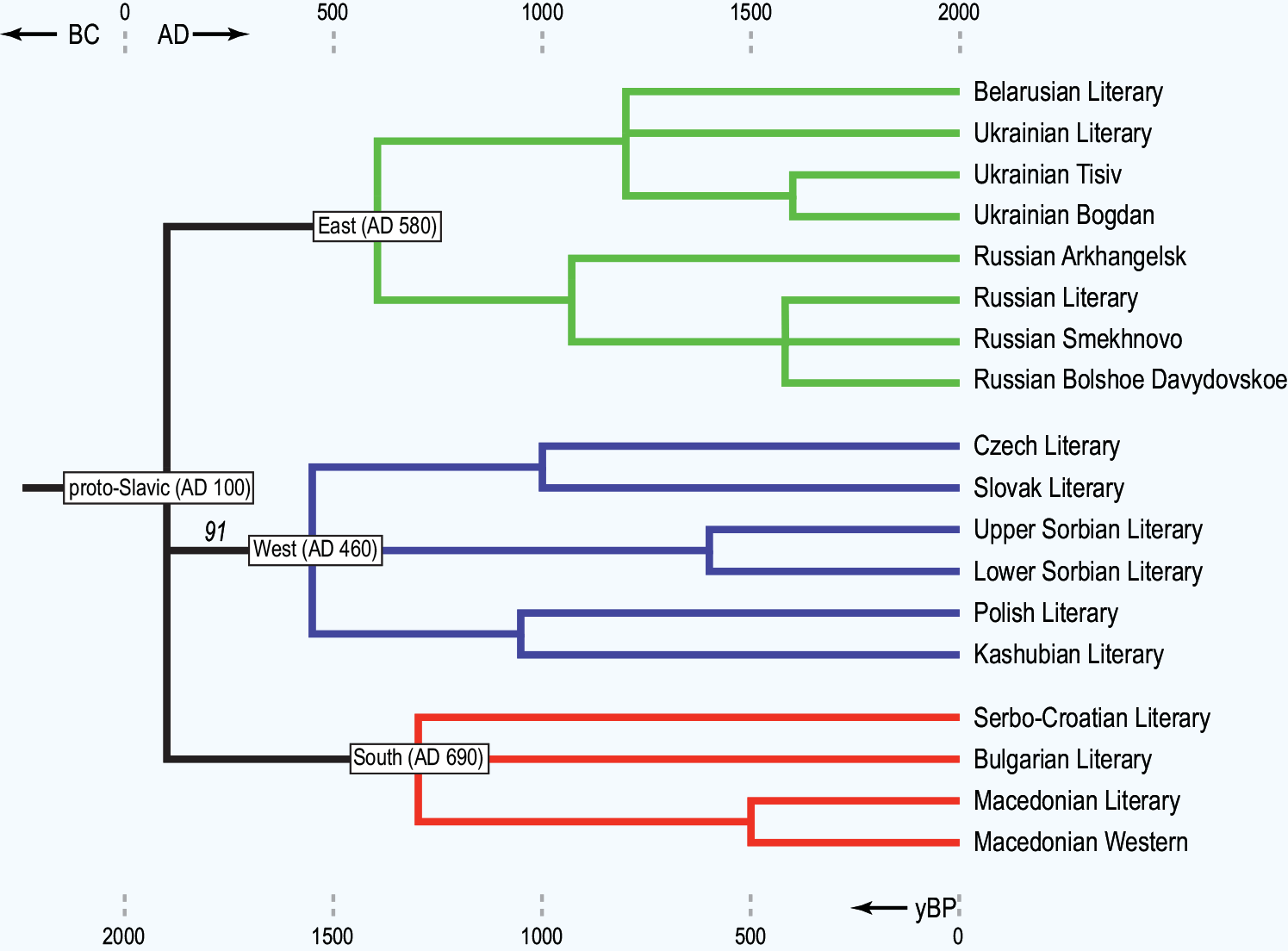
Варто звернути увагу, що на цій взірцевій глоттохронологічній схемі чільного представника московської школи компаративістики зазначено відокремлення російської гілки від українсько-білоруської шостим століттям, що цілком заперечує теорію єдиної східнослов'янської мови Київської Русі, але підтверджує концепцію глоттогенезу цих мов Шевельова.
Ще одним непрямим підтвердженням цієї концепції на схемі Касьяна є одночасне відгалуження білоруської й української мов та галицько-подільських діалектів, що заперечує класичну схему, за якою прамова розпадається на діалекти, з яких розвиваються окремі мови, і в яких, своєю чергою, формуються свої діалекти, – діалекти, як і вказував Шевельов, можуть формуватися раніше за самі мови.
Цілком можливо, що до цих важливих висновків призвело піонерське включення в лексикостатистичну матрицю слов'янських мов списків Сводеша "живих"¹⁹ діалектів, але змішання в одній матриці двох різних мовних категорій: соціально стандартизованих (внормованих) літературних мов та розмовних мов (діалектів) окремих територій несе загрозу деформації реальної картини.
І це (дослідження еволюцій територіальних мов на основі стандартизованих, тобто соціальних) є загальним застереженням до, фактично²⁰, всіх робіт зі слов'янської лексикостатистики і, відповідно, глоттохронології. Звичайно, є висока кореляція між базовими списками цих двох категорій мов, але є і суттєві відхилення: у всіх базових списках, наприклад, болгарської мови фігурує лексема луна, відсутня – так само на всіх лінгвістичних мапах болгарського мовного ареалу – на території Болгарії. Очевидно, що наслідком таких деформацій списків буде деформація результату ("garbage in, garbage out").
Можна запропонувати простий вихід: всеслов'янське соціологічне опитування, де респондентам, що в побуті спілкуються місцевою говіркою, пропонують за методом діагностичних контекстів²¹ одним словом описати Сводешеві поняття. Його може виконати будь-яка соціологічна фірма, інтерв'юери не мусять бути фаховими лінгвістами; фінансування (десь кілька тисяч євро на одну країну), думаю, досяжне національним славістичним комітетам – зате в результаті вони (і всі ми) отримали б певну мовну машину часу.
Але поки цього нема, можна спробувати використати те, що є. А є матеріали Загальнослов'янського лінгвістичного атласу (OLA) – грандіозного проєкту, що почався за рішенням IV Міжнародного з’їзду славістів в 1958 році і ще не завершився. Опитування охоплювали 834 пункти (мовці 13 слов'янських мов) і тривали до 1990 року. Квестіонар атласу включав 3454 питання – серед них, власне, були 98 лексем²² зі 100-слівного списку Сводеша²³.
Результати почали публікувати з 1988 року, до 2020-го вийшло 18 випусків OLA з відповідями на 1224 питання анкети. Планувалося, що до 2024 року будуть онлайн опубліковані всі матеріали²⁴, але через російську агресію робота міжнародної комісії Загальнослов'янського атласу зупинилася²⁵ (останнє із засідань, що з 1966 року відбувалися один-два рази річно, було в 2021 році).
Дві країни (Пн. Македонія і Боснія та Герцеговина) результати опитування на своїй території опублікували повністю, Польща оприлюднила "сирі" дані: скани картотеки опитування зі всіх 88 пунктів на її теренах²⁶; про публікацію своєї бази заявила і Росія, але формуляр на сайті slavatlas.org видає лиш повідомлення "error on connection".
Зі всіх ста Сводешевих концептів п'ятдесят у слов'янських мовах мають однакові когнати; з решти 48 в опублікованих матеріалах є 36; ще чотири є в паралельному проєкті ALE²⁷ (щоправда, з рідшою сіткою: 331 слов'янський пункт). Замість двох відсутніх концептів (kill і bite) можна використати два з модифікованого Яхонтовим списку Сводеша²⁸ (worm і year, матеріали стосовно яких вже опубліковані в лексико-словотворчих випусках OLA). Ареали ж слов'янських відповідників решти шести концептів можна попередньо (поки не будуть опубліковані всі матеріали слов'янського атласу) визначити за національними атласами окремих мов, корпусами діалектних текстів (зокрема, в прикладах словників діалектів), словниками мов тощо. Що і було зроблено: мапи ареалів відповідників цих 50 Сводешевих понять у слов'янських діалектах наведені в додатку²⁹.
Отож, реалізувавши всі ці "можна", перераховані в попередньому абзаці, я розрахував матриці мовних дистанцій слов'янських діалектів. Розрахунок дистанцій проводився сумуванням попарного порівняння всіх пунктів OLA за всіма п'ятдесятьма різнокогнатними поняттями: мовна дистанція між двома пунктами в математичних вимірах певного Сводешевого поняття рівна одиниці, якщо в двох порівнюваних пунктах на його позначення вживають етимони різних когнатів, і рівна нулю – якщо одного і того ж; коли в певному пункті на позначення цього певного поняття вживають два або більше синонімів, то попарне порівняння проводилось з кожним з ним і враховувалась відносна стосовно кількості синонімів сума результатів цих порівнянь³⁰.
Проблема з синонімами є однією з найприкріших у лексикостатистиці: довільний підбір синонімів може суттєво спотворити таксономічну мовну класифікацію³¹.
З іншого боку, синонімія засадничо закладена в Сводешеву ідею поступової заміни прадавньої лексеми на означення певного поняття його списку іншою: заміна не відбувається одномоментно – деякий час в мові паралельно немарковано функціонують стара і нова лексеми. Хоч на цей аспект у лексикостатистичних теоріях і вказується ("один із випадків, коли синонімія є неминучою, – це перехідний етап в історії мови, під час якого старіше слово поступово витісняється новішим замінником"³²), але при складанні списків враховується тільки тоді, коли частота вживання синонімів приблизно однакова (однак методика бінарних значень у таких випадках противиться зважуванню: "дозволена синонімія означає, що коли той самий слот списку Сводеша заповнений більш ніж одним словом, тобто кількома синонімами, в межах цього слоту порівнюються усі можливі пари відповідних слів між двома мовами: якщо існує хоча б одна збіжна пара, увесь слот вважається збігом"³³ – тобто фіксується нульова віддаль, хоч коректніше би було зафіксувати проміжну між цим нулем та величиною, якою позначається відсутність збігу).
В опрацьованих даних OLA кількість випадків з синонімами (пересічно 2,7%) для вказаного 100-слівного списку в цілому вкладається (без жодної селекції) у жорсткі 5-відсоткові рамки "нетолерування синонімів", запропоновані протоколом визначення лексем IE-CoR³⁴ (Indo-European Cognate Relationships): набором чітких і суворих методологічних правил для відбору слів до лексичної бази даних про спорідненість слів у індоєвропейських мовах³⁵.
Отримана в даному дослідженні статистика діалектних даних дозволяє: 1) зважувати синоніми за їх частотою вживання в діалектному ареалі³⁶ і 2) відтворити часову траєкторію витіснення старої лексеми новою³⁷: кількість зафіксованих випадків вживання синонімів (на позначення одного Сводишевого поняття) у певному діапазоні відсоткових пунктів їх частот в різних діалектах показує нормовану до всього етапу заміщення тривалість функціонування лексем в межах цього відсоткового діапазону. Якщо нанести всі ці значення – тобто частоти вживань усіх лексем у всіх діалектах – на координатну вісь у порядку зростання частот, отримаємо типову логістичну поширення інновацій, тобто дещо асиметричну S-подібну криву, що графічно відображає поступове витіснення старої лексеми новою: за перший півперіод цього процесу (п'ять децилів) частота її вживання в ареалі певного діалекту виростає лише до 20% (йде процес конкуренції кількох нових лексем за домінування замість старої: якщо синонімів менше, то крива на цьому етапі зсувається вліво), до сьомого дециля всього періоду частота стає більшою 50%, а до 9-го – 90%, далі витіснення знову дещо сповільнюється.
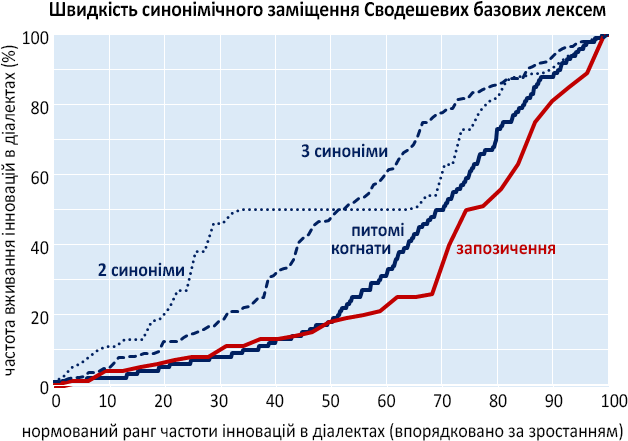
Коли таку саму процедуру провести для визначення часової траєкторії витіснення старих лексем запозиченнями (попередня була для питомих праслов'янських когнатів), то побачимо сильніше виражену асиметрію отриманої S-подібної кривої: довший (до сьомого дециля всього періоду) перший повільний етап входження запозичення в обіг і, відповідно, прискорення на етапі остаточного витіснення (до 20% збільшення частоти за дециль): це може пояснити зафіксовану дослідженнями деформацію глоттохронології запозиченнями (щоб її усунути, запозичення в глоттохронологічних оцінках не враховуються; натомість отримані траєкторії вказують, що і синоніми, і запозичення варто – з корекцією на S-подібну форму еволюції витіснення – включати в розрахунок).
Ото стільки вступних зауваг³⁸. А тепер переходжу, власне, до викладу результатів – мало би стати цікавіше.
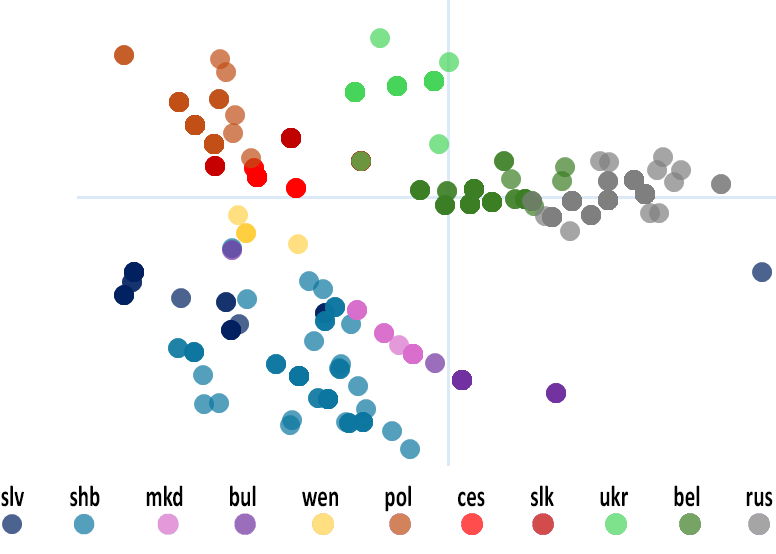
Графічно відобразивши отриману матрицю 797×797 проєкцією на двомірну площину³⁹, де кожна точка відповідає певному пункту опитування, а віддалі між точками максимально наближено відображають мовні віддалі між пунктами⁴⁰, побачимо, що дані групуються в кільканадцять діалектних кластерів різної – сфероподібної або подовгастої ланцюжкової – конфігурації.
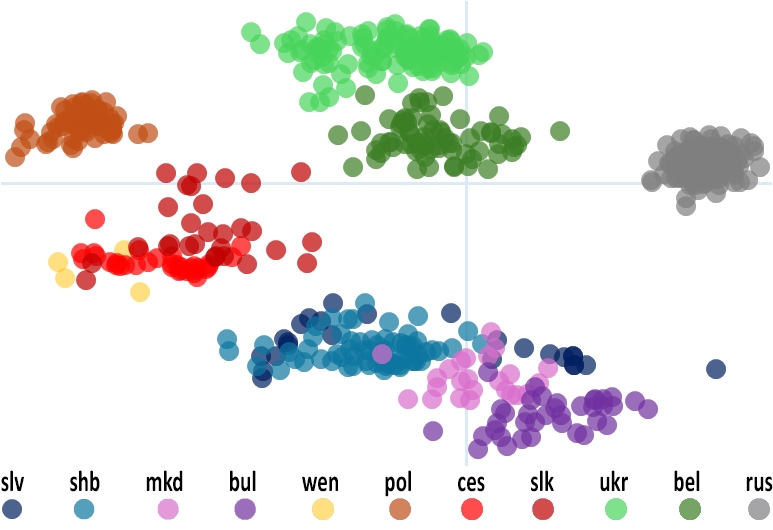
Застосувавши статистичний кластерний аналіз⁴¹, отримаємо 19 діалектних кластерів⁴².
Їхній сучасний географічний розподіл (не факт, що таким він був у праслов'янську епоху) показано на мапі, а середні віддалі між ними – в матричній таблиці⁴³.
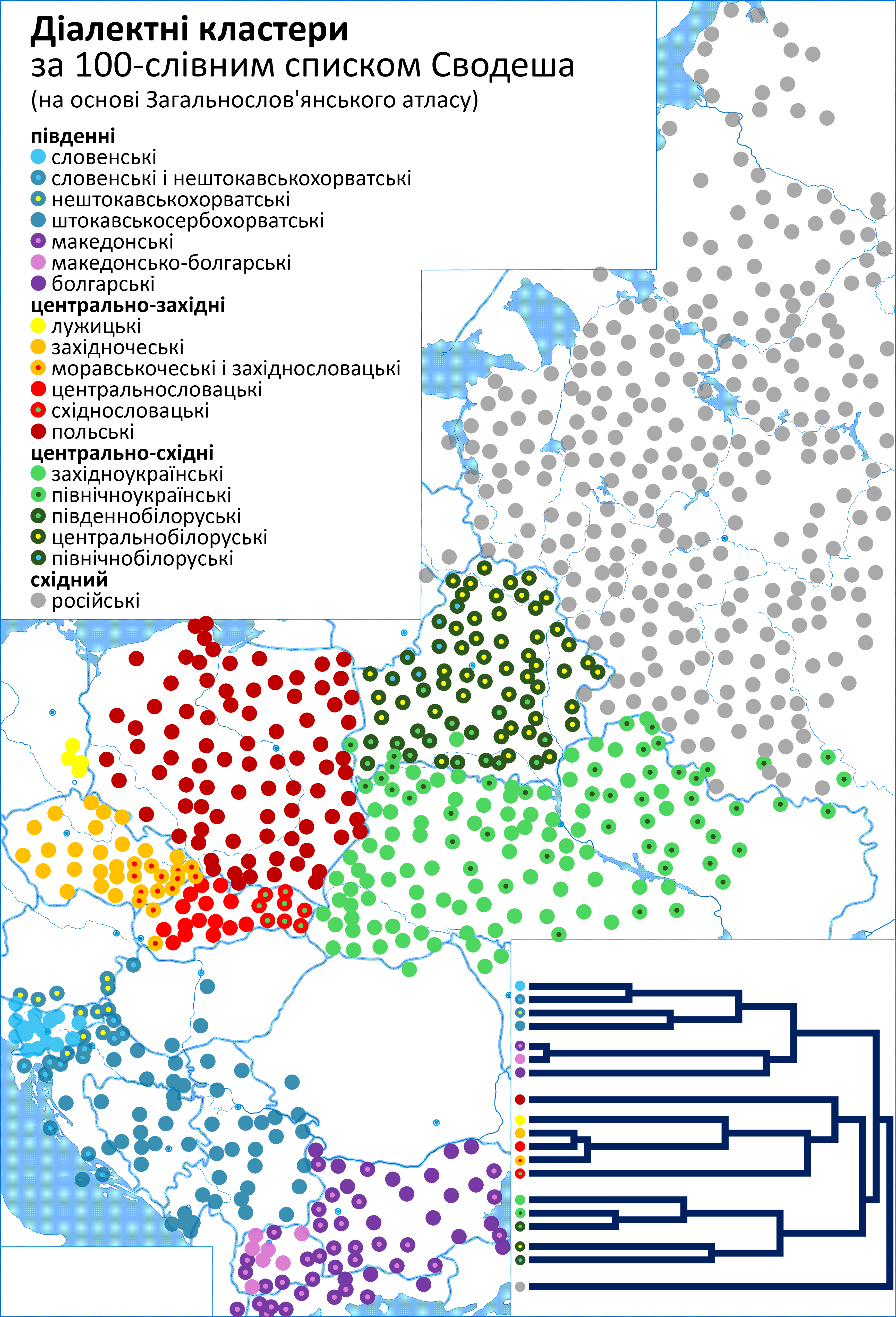
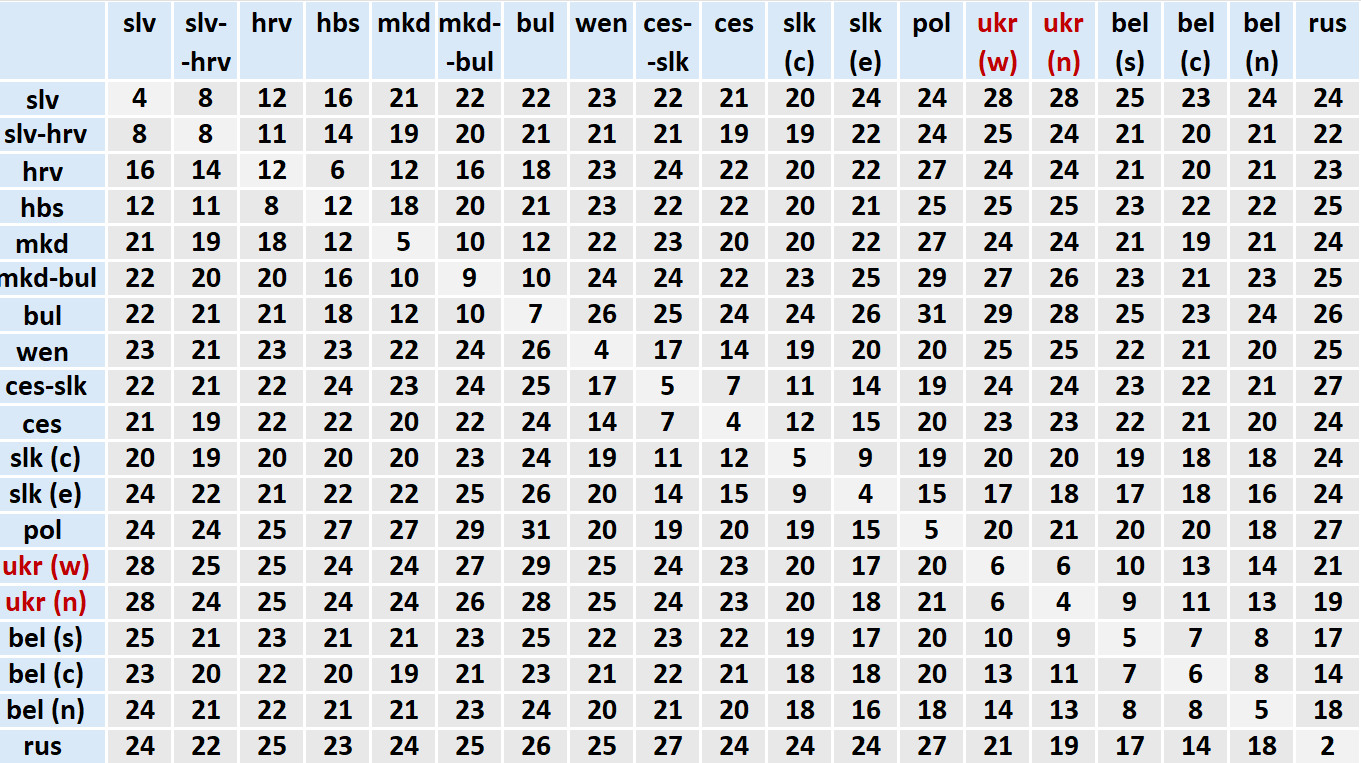
Середні мовні віддалі від українських діалектних груп до кожного слов'янського пункту показані на двох наступних мапах (для решти діалектних груп – у додатку)
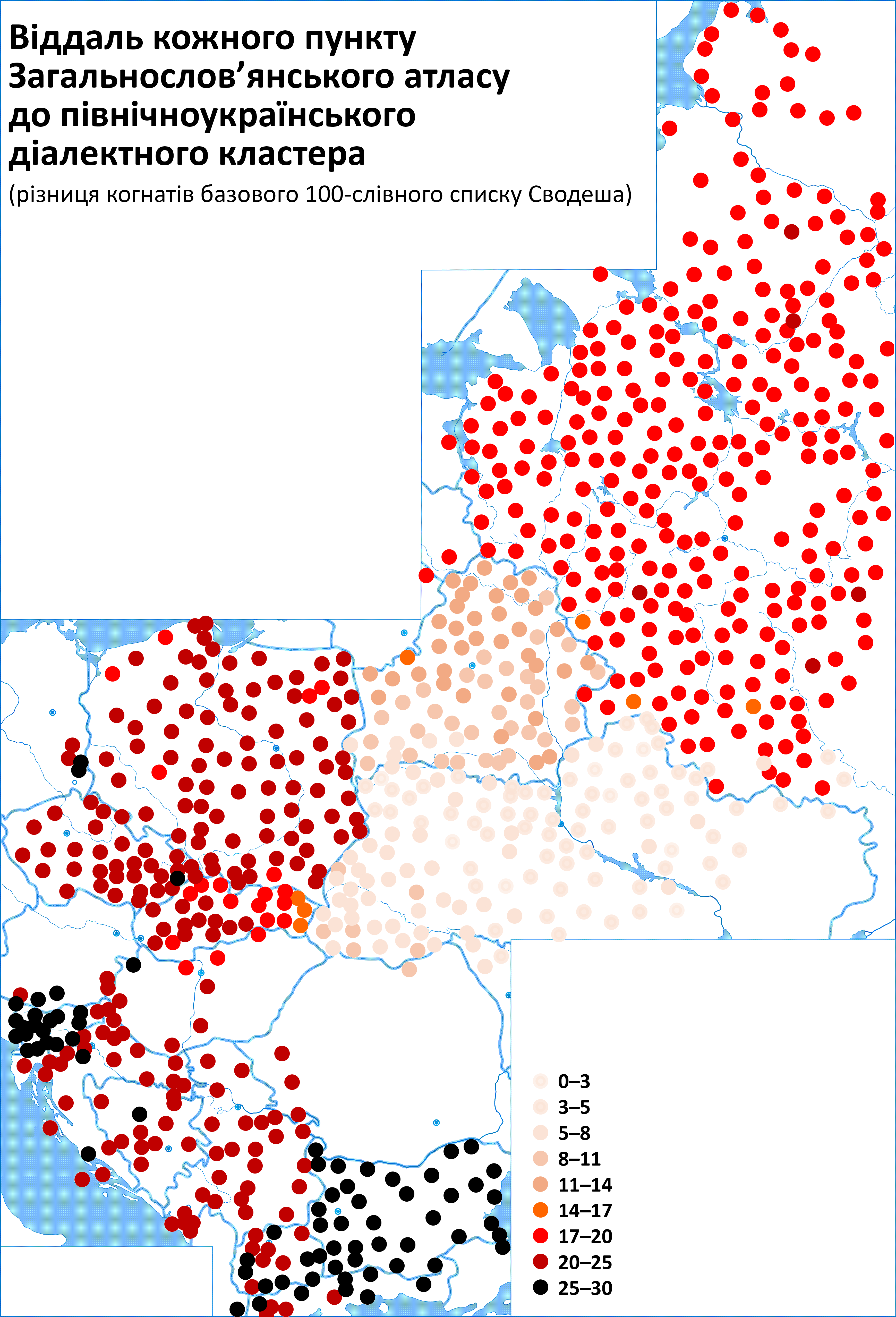
Варто зауважити (в контексті питання про українсько-російську близькість "братніх мов"), що для 113 зі 124 пунктів в Україні східнословацька діалектна група (незаслужено не називана "братньою") є мовно ближчою за російську; причому для 57 з них (і не тільки на Галичині) ближчою за російську є і польська мова.
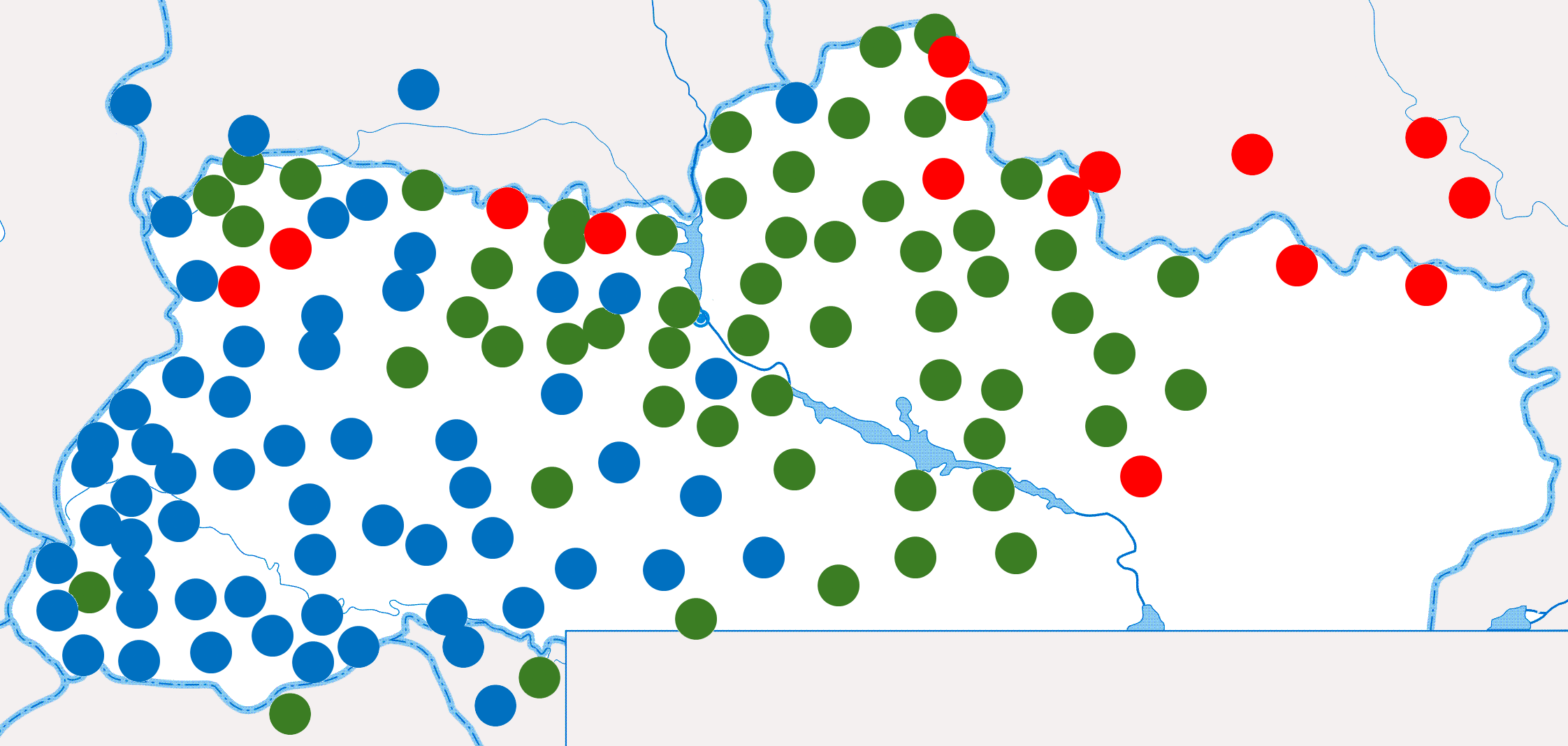
Синім позначено пункти, де ближчою за російську є і східно-словацька, і польська діалектні групи, зеленим – східно-словацька, червоним – де ближчою є російська діалектна група.
Але більш системну картину взаємозв’язків дає таксономічна (ієрархічна) дендрограма⁴⁴, що є результатом математичної (алгоритмічної) реконструкції генетичних зв’язків між діалектними групами (цифри у вузлах – відсоткові Сводешеві мовні віддалі між гілками).

Не входячи в дискусію стосовно абсолютної хронології процесів відокремлення окремих діалектних груп, з цієї дендрограми можна зробити висновок про послідовність етапів глоттохронології.
На початках праслов'янська діалектична єдність почала диференціюватися на три кластери: південну, західну (а радше центральну) та східну групи, що відповідає віддавна усталеній схемі. Нетиповим є склад двох останніх груп (південна група передбачувано ділиться на болгарсько-македонську та словено-сербохорватську підгрупи): східна група включає лиш російські діалекти, натомість білорусько-українська, яка традиційно включається разом з російською в східнослов'янську групу праслов'янських діалектів, входить разом із західнослов'янськими діалектними групами в центральнослов'янську, утворюючи там східну підгрупу. А далі ця підгрупа ділиться на два менші кластери: властиво білоруський і українсько-білоруський, який, своєю чергою, ділиться на властиво український та, знову ж таки, білорусько-український – в якій впізнаємо галицько-подільську та києво-поліську групи діалектів історичної фонології української та білоруської мов Юрія Шевельова.
Шевельов не дружив з математикою; в методологічних зауваженнях до своєї "Передісторії слов'янської мови" він висловив прихований скепсис до "шлюбу" математики з лінгвістикою і спеціально зазначав, що стосує винятково "лінгвістичну лінгвістику"⁴⁵. В "Історичній фонології української мови" він, підсумовуючи тенденції, що згодом стали характеристичними для української мови, все ж спробував кількісно оцінити ступінь незалежності кожної звукозміни, що заторкнула протоукраїнські діалекти, – і помилився з коефіцієнтом часткових змін⁴⁶. І ось через десятки років саме алгоритмічна математика дає навздогін лексико-статистичне підтвердження його теорії фонологічної еволюції праслов'янських діалектів.
Заанонсую, що ця теорія Шевельова знайде ще одне підтвердження⁴⁷, а наразі повернімося до дендрограми. Найбільш таксономічно складною є західно-центральна група діалектів: спочатку в ній виділяється кластер польських діалектів, далі з чесько-словацько-лужицької групи – кластер східнословацьких діалектів, а потім лужицьких; а чесько-словацьке ядро парцелюється на три групи: властиво чеські (західні) діалекти, властиво словацькі (центральні діалекти) та групу східночеських (моравських) і західнословацьких діалектів.
Згадувана болгарсько-македонська підгрупа південнослов'янської групи діалектів розпадається на властиво болгарську та близькі групи західномакедонських і македонсько-болгарських діалектів.
Словено-сербохорватська ж підгрупа теж розпадається на кластери, кожен з яких – ще на два: словенських і нештокавськохорватських (тобто чакавських і кайкавських) діалектів та – в іншій гілці – словенсько-хорватських (тобто нештокавських) і штокавських сербохорватських діалектів.
І ще одне важливе спостереження: якщо будувати дендрограму на основі віддалей між виділеними кластерами, а не між елементами, що формують ці кластери, то її геометрія змінюється – стає усталеною схемою з окремою групою трьох східнослов'янських мов.
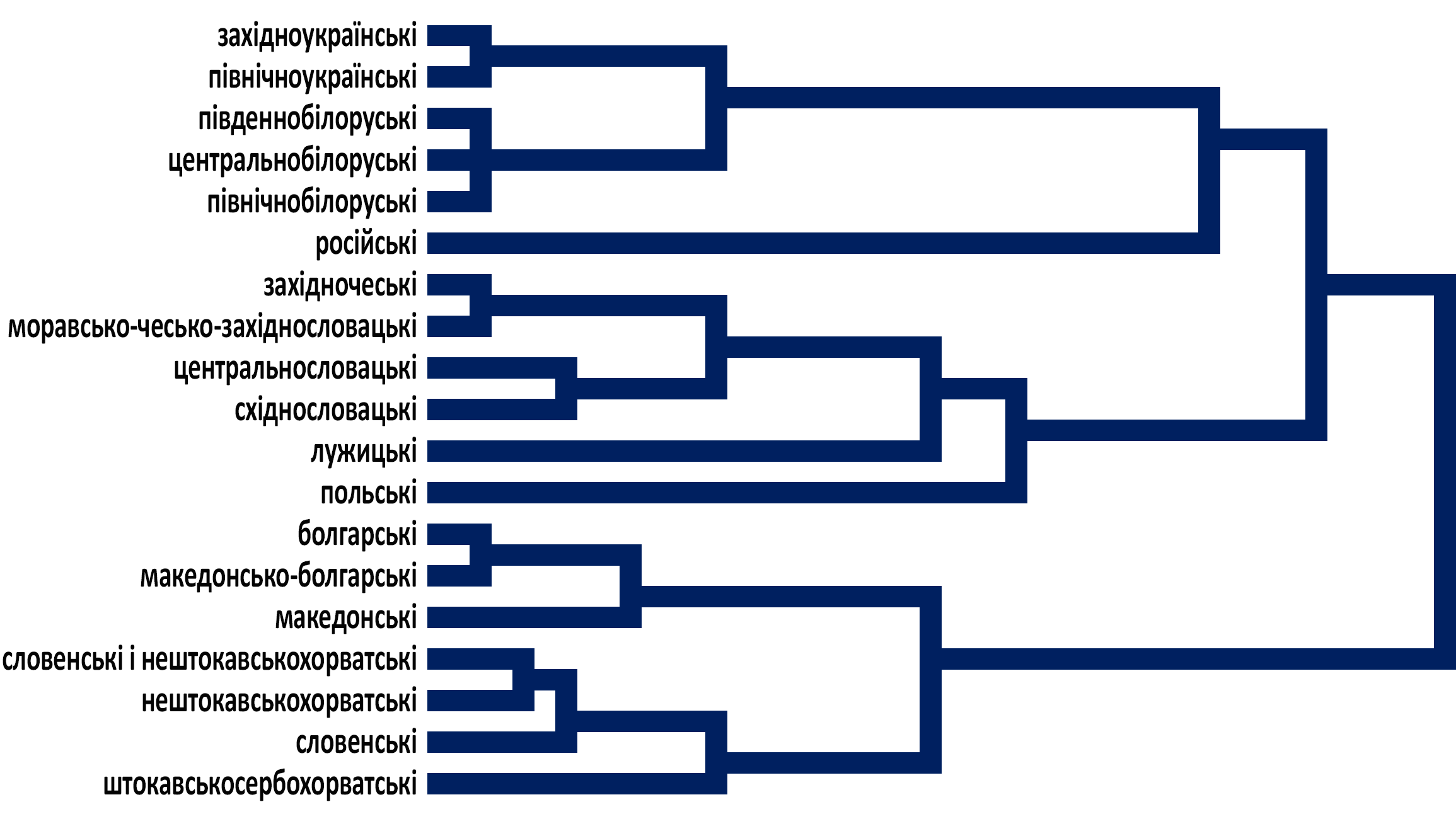
Розбіжність у геометрії дендрограм в цьому випадку відображає фундаментальну різницю між об'єктом аналізу: перша показує природний генеалогічний процес, тоді як друга – результат соціолінгвістичної абстракції. Перша коректно візуалізує реальні генеалогічні зв'язки між діалектними групами, реконструйовані на основі топології діалектного континууму з його особливостями, відображеними у витягнутих ланцюжкових та сфероподібних кластерах. Натомість побудована на основі агрегації – редукції даних, яка концептуально подібна на процес кодифікації мови – нівелює інформацію про внутрішню топологію континууму, примусово "згортаючи" цілі діалектні ланцюги в одиничні, "квазісферичні" сутності. Таким чином, друга дендрограма показує ієрархію зв'язків уже не між живими діалектами, а між їхніми абстрактними "центрами". Цілком очікувано, що ця нова геометрія може корелювати з літературними мовами – соціолінгвістичним феноменом, чия "генеалогія" часто є результатом стандартизації та ідеологічних впливів⁴⁸, що накладаються поверх природного діалектного ландшафту – але не з генеалогією "живої" мови людей певної спільноти.
На цьому можна би було завершувати, але є теоретична можливість заглянути глибше. Згадуваний вже професор С. Яхонтов запропонував виділити в Сводешевому списку максимально стійкий пласт лексики обсягом 35 слів. Відповідно, побудована на основі цього пласту дендрограма має оприявнити часово глибші генетичні зв'язки.
Виконавши необхідні розрахунки, отримаємо матрицю віддалей між пунктами прадавніх діалектів і, відповідно, їх проєкцію⁴⁹ на двомірну площину та дендрограму з виділеними 14 діалектними кластерами і мапу сучасного їх географічного розміщення.
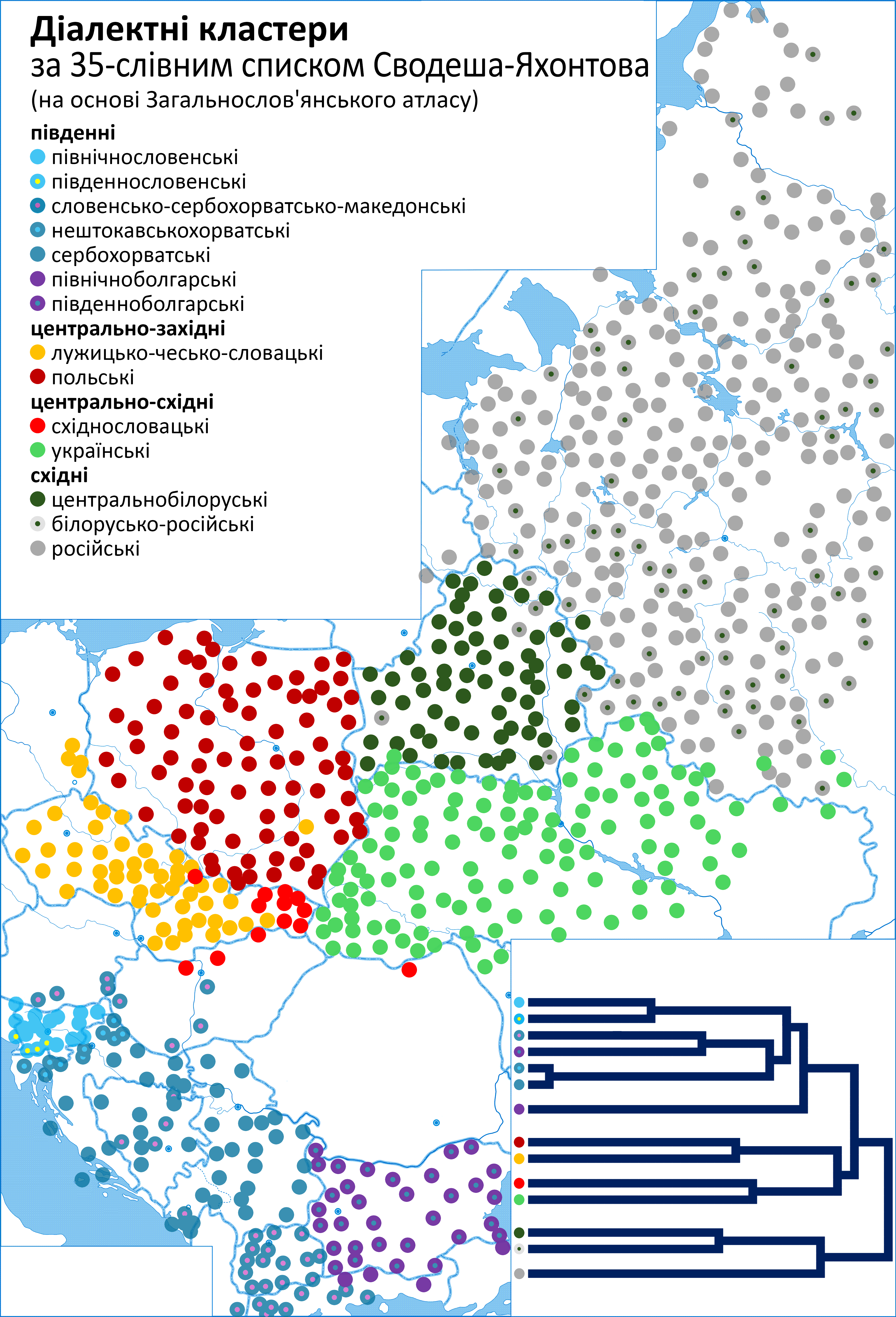
Знову бачимо ті самі три великі групи слов'янських діалектів: південні, центральні та східні.

Але східна група на цій генеалогічній схемі розбивається на кілька кластерів: властиво російську та російсько-білоруську, яка, своєю чергою, диференціюється на властиво білоруську на білорусько-російську, в якій (тримаючи в пам'яті попередню дендрограму) знову впізнаємо схему формування трьох народів сходу Славії, а також мапу ізоглос Геннінґа Андерсена.

Схема формування української, білоруської і російської мов за Ю. Шевельовим.⁵⁰
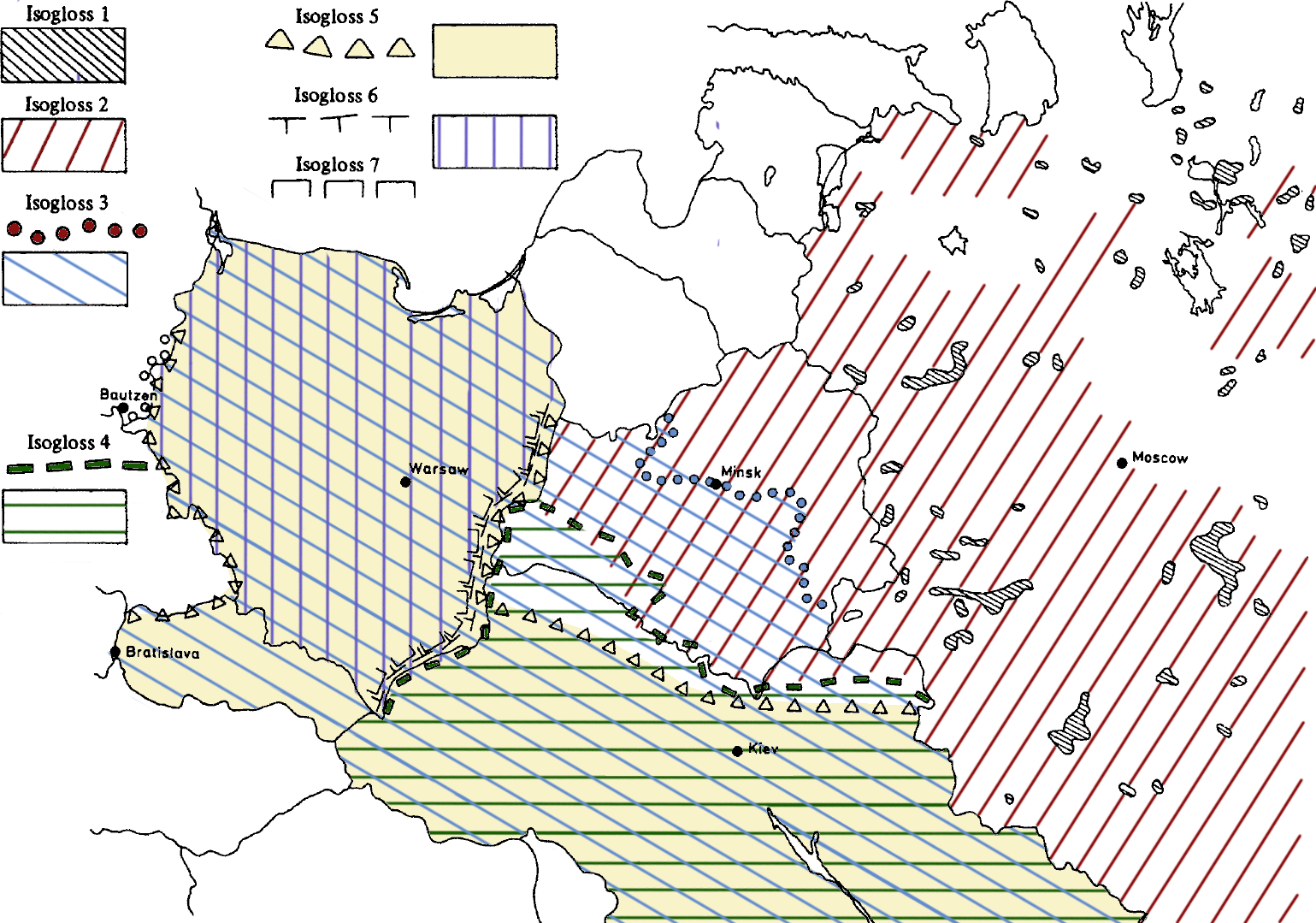
Мапа ізоглос центрально-східних слов'янських мов Геннінґа Андерсена⁵¹.
Так само на два великі кластери розбивається на цій генеалогічній схемі центральнослов'янська група діалектів: східнословацьких та українських діалектів (південно-східна підгрупа) та польських і чесько-словацько-лужицьких діалектів (північно-західна).
Південна ж група слов'янських діалектів розбивається на три підгрупи кластерів: північноболгарських діалектів, словенських діалектів та групу чотирьох дрібніших діалектних кластерів: південноболгарських, македонських з домішкою кількох тепер сербохорватських та словенських пунктів, нештокавських хорватських та штокавських сербохорватських.
У контексті конвергентної концепції Андрія Даниленка про ареально-типологічну включеність української мови в центральноєвропейський мовний союз (Sprachbund)⁵² лексикостатистичний аналіз надає їй генетичної глибини: поверхнева типологічна подібність слов'янських мов Центральної Європи виявляється відображенням глибшої глоттогенетичної спорідненості.
Підсумовуючи, можна ще раз повторити, що "мусимо – не без задоволення – визнати: розвиток слов'янської історичної лінгвістики верифікував постулат Шевельова про те, що диференціація діалектів, які стали основою сучасної української мови, почалася ще в надрах загальнослов'янської спільності, а тому теза про те, що давньоруська мова була спільним предком трьох східнослов'янських мов, є антинауковою фікцією"⁵³. Цього разу це ще раз доведено математичними алгоритмами.
І це породжує хоч малу, але надію, що ще за мого життя українським студентам замість застарілої схеми позаминулого століття будуть викладати саме цю теорію Юрія Шевельова – причому викладати саме в Україні⁵⁴, а не тільки тим, що навчаються на Заході⁵⁵.
Додатки:
Слов'янські ареали Сводешевих базових понять
Віддаль кожного пункту Загальнослов’янського атласу до кожного діалектного кластера
____________
¹ Teun A. van Dijk. News As Discourse. 1988. 200 р.
² Matej Šekli. On The Genealogical Linguistic Classification Of Slavic Languages And Their Dialect Macro-Areas. Dialectologia. Special issue, 11 (2023), 5–49.
³ Таке помилкове ототожнення старослов'янської літературної мови як розмовної мови східних слов'ян часто використовували як аргумент спільної східнослов'янської мови, проміжної між праслов'янською та українською, російською і білоруською. Хоча минулий час вжитого в попередньому реченні присудка є оптимістичною пересадою – адже його, цей аргумент, далі використовують. Що більше: в програмах курсу "Історія української літературної мови" (відповідь на питання, чому тільки літературної, а не мови як такої в її комунікативному розмаїтті, треба шукати, мабуть, у спадковості радянських парадигм) українських університетів вона, ця "східнослов'янська" літературна мова, далі подається яко предок української мови.
⁴ August Schleicher. Compendium der vergleichenden Grammatik der indogermanischen Sprachen. (Kurzer Abriss der indogermanischen Ursprache, des Altindischen, Altiranischen, Altgriechischen, Altitalischen, Altkeltischen, Altslawischen, Litauischen und Altdeutschen.) (Bd. 1–2, 1861–62). 764 S.
⁵ James Clackson. Methodology in Linguistic Subgrouping. In: The Indo-European Language Family. A Phylogenetic Perspective. (2022). p. 18–32.
⁶ Johannes Schmidt. Die Verwantschaftsverhältnisse der indogermanischen Sprachen. (1872). 68 S.
⁷ Paul Heggarty, Warren Maguire, April McMahon. Splits or waves? Trees or webs? How divergence measures and network analysis can unravel language histories. Phil. Trans. R. Soc. B (2010) 365, 3829–3843.
⁸ George Y. Shevelov. A Prehistory of Slavic: The Historical Phonology of Common Slavic. Heidelberg: Winter, 1964. 662 p. (амер. видання: New York: Columbia University Press, 1965. Pages xx, 662 p.).
⁹ ibid., p.611-612.
¹⁰ "Хоч як парадоксально це звучить, але поділ діалектів на північні та південні в українській мові є давнішим від самої української мови, що вона, власне, й виникла завдяки злиттю цих двох діалектних угруповань" (Юрій Шевельов. Історична фонологія української мови. 2002. с. 961).
¹¹ Юрій Шевельов згадував, що Геннінґ Андерсен відвідував його лекції (див. його "Зустрічі з Романом Якобсоном"); в роботах Андерсона можна бачити визнання ним авторитету Шевельова.
¹² Henning Andersen. On the formation of the Common Slavic koiné. In: New perspectives on the early Slavs and the rise of Slavic: Contact and migration (2020), 11–42.
¹³ Можна згадати, наприклад, Степана Смаль-Стоцького (Stephan Smal-Stockyj und Theodor Gärtner. Grammatik Der Ruthenischen (Ukrainischen) Sprache. (1913). S. 455–495.)
¹⁴ Пізніше спробу іншого підходу – розрахувати рівень спорідненості на основі вже всього корпусу опублікованих випусків (проєкт триває) "Етимологічного словника слов'янських мов" здійснили Валентин Стецюк (Определение мест поселения древних славян графоаналитическим методом. Известия Академии Наук СССР. Серия литературы и языка. Том LXIV. № 1, 1987) та Анатолій Журавльов. (Лексикостатистическая оценка генетической близости славянских языков. Вопросы языкознания, 1988, 4, 37–51; Лексико-статистическое моделирование системы славянского языкового родства. Индрик, Москва 1994).
¹⁵ Alexei Kassian. Lexicostatistics. Іn: Encyclopedia of Slavic Languages and Linguistics Online. (2023). Як продовження цього огляду виглядає його цьогорічна стаття (разом з Г. Старостіним: Alexei S. Kassian, George Starostin. Do ‘language trees with sampled ancestors’ really support a ‘hybrid model’ for the origin of Indo-European? Thoughts on the most recent attempt at yet another IE phylogeny. Humanit Soc Sci Commun 12, 682 (2025).) з критичною оцінкою останньої (2023 року) моделі групи 32 науковців на чолі з Пол Геґґерті з Інституту еволюційної антропології ім. Макса Планка: P.Heggarty,C.Anderson, M.Scarborough et al. Language trees with sampled ancestors support a hybrid model for the origin of Indo-European languages. Science, 2023, vol. 381 (issue 6656): eabg0818.
¹⁶ З дещо формальнішим (і більш куцим) переліком можна ознайомитися також в розділі лексикостатичних моделей огляду еволюції генетичної класифікація слов'янських мов за 350 років В. Блажека того ж 2023 року: Václav Blažek. Genetická klasifikace slovanských jazyků – 350 let evoluce klasifikačních modelů. Slavia, 2023, roč. 92, č. 5, s. 513–537.
¹⁷ Зокрема, непрозорості закладених апріорних обмежень в методах баєсового висновування (підбір найімовірнішого генетичного дерева: "кожну з трьох слов’янських гілок було вручну наперед визначено як окрему кладу ще до початку аналізу. Іншими словами, спершу комп'ютерній програмі було повідомлено, який результат мають намір отримати дослідники, а потім програма видала бажане дерево") – Ейпріл та Роберт МакМагони влучно назвали це "прецедентним правом" компаративістики (A. McMahon and R. McMahon. Language Classification by Numbers. 2005); скептично оцінено – у випадку добре досліджених мовних сімей – також спробу автоматизованого оцінювання подібності на основі фонологічної подібності (т. зв. відстань Левенштейна – кількість необхідних фонологічних змін для трансформації слова в одній мові в іншомовний відповідник) замість етимологічного походження; згадано і про мережі: зазначено, що програмні пакети, що використовуються для лексикостатистики, запозичені з біології, переважно з молекулярних досліджень, і не були розроблені для лінгвістики, також досі залишається відкритим питання, який із багатьох доступних математичних алгоритмів краще відповідає еволюції природної мови.
¹⁸ A.Kushniarevich, O.Utevska, M.Chuhryaeva, A.Agdzhoyan, K.Dibirova, I.Uktveryte, et al. Genetic Heritage of the Balto-Slavic Speaking Populations: A Synthesis of Autosomal, Mitochondrial and Y-Chromosomal Data. PLoS ONE, 2015, v.10(9): e0135820.
¹⁹ Для формування діалектних списків двох західноукраїнських пунктів використано польові записи з архіву Сєрґєя Ніколаєва 1990-х років, коли той займався дослідженням лінгвоґенезу слов'ян (див., напр., Николаев С. Л. Раннее диалектное членение и внешние связи восточнославянских диалектов. Вопросы языкознания. 1994, № 3. с. 23–49.)
²⁰ Пізніше, 2020 року, М. Васільєв і М. Саєнко опублікували схему слов’янського глоттогенезу, цілком побудовану на основі 25 діалектних 110-слівних списків (М. Е. Васильев, М. Н. Саенко. Анализ топологии и оценка точности лексикостатистических классификаций (на примере славянских языков). Journal of Language Relationship, 2020, 18 (3–4), р. 320–347), пояснюючи такий підхід тим, що літературні мови мають тенденцію штучно зберігати лексичну норму. Однак А. Касьян слушно зауважив у своєму огляді, що формування списку базової лексики за допомогою діалектних словників спотворює цей перелік, оскільки такі словники заточені на пошук лексики, що відрізняє діалект від літературного стандарту, яка для носія цього діалекту може бути хоч і зрозумілою, але маркованою і рідковживаною (екзотичною).
²¹ Опис див. у статті A.Kassian, G.Starostin, A.Dybo, V.Chernov. The Swadesh wordlist. An attempt at semantic specification. Journal of Language Relationship, 2010, 4, pp. 46–89.
²² Не всі ці лексеми точно відповідають згаданим діагностичним контекстам, але всі є семантично близькими до Сводешевих понять і, головне, однаковими для всієї вибірки – на відміну, скажімо, від згаданого в прим. 19 дослідження, де, наприклад, для концепту fat (з приміткою в контекстному описі "відрізняти спеціально оброблений чи приготований жир") поряд із літературно українським жир вжито в західноукраїнських діалектних списках смалець і сало – які тут, власне, означають спеціально оброблений чи приготований жир.
²³ Варто зазначити, що не всі ці слова були в лексико-словотворчій частині анкети: когнати деяких праслов'янських етимонів зі списку Сводешевої базової лексики поміщені в OLA з огляду на фонетичну, а не семантичну еволюцію. Напр., когнати *pьrsi в польській мові (pierś) відповідають Сводешевому концепту breast, а в українській мові це значення стало маркованим (архаїзувалося): у своєму основному значенні перса означають (поетизовано) 'жіночі груди'. Однак у більшості відповідей на такі питання стосовно фонетичних аспектів є вказівки на слова базового списку; напр., в питанні 1629FM (*sьrdьce) відсутність відповіді в лужицьких респондентів вказує на інше вживане тут слово для концепту heart (wutroba/wutšoba); у питаннях 2446F (*dъžǯь) в кількох пунктах респонденти повідомляли, що на дощ (rain) в них кажуть kìša або godina.
²⁴ Peter Weiss. Vzporedna predstavitev (slovenskih) jezikovnih pojavov po gradivu za narečne atlase. Hrvatski dijalektološki zbornik, 2018. 22. s. 141–153.
²⁵ Приватне повідомлення координатора цього проєкту Петера Вейса; принагідно висловлюю йому вдячність за надані скани відсутніх в українських бібліотеках випусків OLA.
²⁶ Скани картотеки оприлюднено буквально недавно, 18 вересня, вже в процесі підготовки цієї статті: раніше вони були доступні тільки в комп'ютерній мережі Інституту польської мови ПАН, однак після мого звернення доступ зробили публічним, за що вдячний д. Дороті Міка.
²⁷ Atlas Linguarum Europae (Лінгвістичний атлас Європи) – запропонований на Другому міжнародному конгресі діалектологів у 1965 році й запущений у 1970 році проєкт лінгвістичних опитувань із 2631 пункту, 51 країни і 90 мов; з 1985 по 2015 рік вийшло дев'ять випусків з мапами та коментарями до них.
²⁸ Петербурзький орієнтолог С. Яхонтов (1926–2018) запропонував замінити десять слів стандартного 100-слівного списку Сводеша словами з другої сотні його розширеного списку (С. Старостин. О доказательстве языкового родства. "Типология и теория языка" (к 60-летию А.Е. Кибрика), с. 57–69, 1999.
²⁹ В 37 пунктах (з 834) опитування проводили за скороченою програмою, їхніх даних до уваги не брали; в інших були спорадичні пропуски відповідей на окремі питання опитувальника – у цих випадках відповідь апроксимувалася з навколишніх пунктів (якщо вони очевидно вказували на найвірогідніший варіант пропущеної).
³⁰ Тобто розрахунок проводився за формулою:
Rxy = Σk {Σsₖ |xₖᵢ–yₖᵢ| /[ Σ sₖ |xₖᵢ–yₖᵢ|+ Σ sₖ (xₖᵢ⋅yₖᵢ)]}
де
Rxy – Сводешева мовна віддаль між двома пунктами х та у OLA;
k = 1...50 – почергові п'ятдесят Сводешевих понять, для яких у слов'янських діалектах є відповідники від різних когнатів;
sₖ – кількість відповідників k-го Сводешевого поняття в слов'янських діалектах;
i=1 ... sₖ – синоніми-відповідники k-го Сводешевого поняття в слов'янських діалектах;
xₖᵢ=0 (чи yₖᵢ=0), якщо етимон i-го слов'янського відповідника для k-го Сводишевого поняття в говірці пункту x (чи, відповідно, y) не вживають;
xₖᵢ=1 (чи yₖᵢ=1), якщо етимон i-го слов'янського відповідника для k-го Сводишевого поняття в говірці пункту x (чи, відповідно, y) вживають.
³¹ Ґрунтовний огляд А. Касьяна некоректних включень синонімів див. в додаткових матеріалах до згаданої вже статті A. Kushniarevich et al. Genetic Heritage... (прим. 19).
³² A.Kassian et al. The Swadesh wordlist... (2010).
³³ A.Kushniarevich et al. Genetic Heritage... (2015).
³⁴ Проєкт Indo-European Cognate Relationships (IE-CoR) створено під егідою Інституту еволюційної антропології Макса Планка у межах дослідницької програми лінгвістичної та культуральної еволюції; покриває приблизно 170 базових понять у 160 індоєвропейських мовах.
³⁵ Cormac Anderson et al. The Indo-European Cognate Relationships dataset. Scientific Data, 2025. 12. 10.1038/s41597-025-05445-3.
³⁶ Це використано в даному дослідженні.
³⁷ А це чекає свого використання в корегуванні глоттохронічних досліджень, але в даному дослідженні обґрунтовує врахування і синонімів, і запозичень.
³⁸ На марґінесі ще можна би було застерегти від спостережуваної тенденції пересадної уваги – в сенсі визначення генеалогії мов – до спільних лексичних інновацій (застереження не стосується фонологічних інновацій), а не до спільної збереженої лексики: звикло нові лексеми, що за Сводешевим механізмом витісняють прадавні, в мові вже існують, тільки змінюється їх семантичний статус чи знімається маркованість. Тобто вибір інновацій при витісненні старої лексеми в половині всіх випадків обмежується одним–двома варіантами, отже випадковий збіг інновацій не є нескінченно малою ймовірністю, а цілком відчутною величиною, яку треба враховувати при аналізі. Те саме із запозиченнями: однакові запозичення не обов'язково мусять свідчити тільки про генетичну спорідненість – але й про спільного мовно впливового сусіда.
³⁹ Застосовано багатовимірне масштабування (PROXSCAL) з мінімізацією нормалізованого простого стресу, в результаті отримано високу якість відображення: normalized raw stress = 0.027; S-stress = 0.065; Tucker’s congruence = 0.986; VAF = 0.973 (майже ідеальне збереження топології) – тобто двовимірна конфігурація адекватно відтворює структуру діалектного континууму.
⁴⁰ Верхню межу середньої похибки цих мовних віддалей можна оцінити, виходячи із різниці між двома мовно суміжними пунктами, віддаль між якими в ідеальному випадку мала би бути нульова або, точніше, рівна градієнту діалектного континууму в межах одного кластера; відповідні розрахунки вказують, середнє відхилення віддалей від ідеального випадку є на рівні 1,48%.
⁴¹ З огляду на згадану морфологічну неоднорідність кластерів (наявність як компактних сфероподібних груп, так і витягнутих ланцюжкоподібних структур) та нерівномірності вагових представлень мовних ареалів (при якій кожен кластер повинен трактуватися як окрема мовна одиниця незалежно від кількісного обсягу), застосовано метод медіанної кластеризації – оскільки він є компромісним між методом найближчих сусідів (single linkage), який схильний до ланцюжкового ефекту, та методом середнього міжгрупового зв’язку (UPGMA), схильного до надмірного створення компактних кластерів.
⁴² Кластери з одного-трьох пунктів не брались до уваги, оскільки для їх верифікації потрібна дрібніша сітка опитувань; мінімальна кількість в чотири пункти (середня похибка, відповідно, 0,7%) визначалась тим, що в програмі OLA було лиш чотири лужицькі пункти (наступні найменші кластери: один з білоруських – 6 пунктів, один з македонських – 7 та один зі словацьких – 8: середні похибки від 0,5 до 0,6%).
⁴³ Відоме значення середньої похибки дає можливість статистичним бутстрепом (тобто генеруванням кількох сотень мутацій базової матриці з випадковим відхиленням в межах похибки) оцінити – через індекс Жаккара – стабільність отриманих кластерів: нестабільні (а саме диференціація українсько-білоруських, західно- і моравсько-чеських, західноболгарських і македонських, сербохорватських, а також словенських і нештокавсько-хорватських) відзначені на діаграмі.
⁴⁴ Під рубрикою "Чи знаєте ви?" можна відзначити, що:
– найбільша мовна віддаль між слов'янськими пунктами – між болгарською говіркою нині грецького села Калапот та польською говіркою села Яблонка на кордоні зі Словаччиною: 35 різних слів з 100-слівного списку Сводеша;
– аналогічно, найбільша мовна віддаль між діалектними кластерами – між болгарськими та польськими (31 слово).
⁴⁵ "В середині XIX століття майбутнє лінгвістики часто розглядалося як пов'язане шлюбними узами з біологією. Пізніше це було замінено психологічними узами, які в даний час замінюються шлюбом з математикою. Автор цієї книги, не заперечуючи співпраці з будь-якою галуззю природничих та гуманітарних наук, де це може бути корисним, схильний дотримуватися лінгвістичної лінгвістики" (George Y. Shevelov. A Prehistory of Slavic... p. VIII).
⁴⁶ Взявши коефіцієнт 1,5 замість очевидного 0,5 (Юрій Шевельов. Історична фонологія... с. 270).
⁴⁷ Принагідно тут ще можна зазначити, що т. зв. інверсія в отриманій дендрограмі (тобто ситуація, коли середня відстань між елементами кластера вищого порядку є меншою за середню відстань між елементами одного з кластерів, які об’єднуються в нього – на нашій дендрогамі числа в таких вузлах позначені жовтою барвою) таксономічно сигналізує, що діалектна система Славії має мережеву, а не строго деревоподібну природу, тобто подібність формується не лише вертикально (через спільне походження), а й горизонтально (через контакти чи конвергенції) – що, нагадаю, і зазначав Шевельов у своїй "Передісторії слов'янської мови".
⁴⁸ Яко приклад можна згадати знайомі нам кампанії вичищення української літературної мови від галицизмів, тавруючи їх полонізмами.
⁴⁹ Багатовимірне масштабування (PROXSCAL) з мінімізацією нормалізованого простого стресу: normalized raw stress = 0.023; S-stress = 0.061; Tucker’s congruence = 0.989; VAF = 0.967 – тобто двовимірна конфігурація адекватно також відтворює структуру діалектного континууму.
⁵⁰ Юрій Шевельов. Чому общерусский язык, а не вібчоруська мова? (З проблем східнослов’янської глотогонії). Київ: Academia, 1994, 32 с.
⁵¹ Henning Andersen. Perceptual and conceptual factors in abductive innovations. In: Recent Developments in Historical Phonology, ed. by Jacek Fisiak, 1978, p. 1–22.
⁵² Andrii Danylenko. Ukrainian in the Language Map of Central Europe: Questions of Areal-Typological Profiling. Journal of Language Contact. 2013, 6 (1), р.134-159.
⁵³ Орест Друль. Не заперечена теорія ґенези української мови Шевельова. Zbruč, 09.04.2024.
⁵⁴ До сих пір в українських університетських курсах застаріла схема позаминулого століття подається студентам не як історіографічний артефакт чи ідеологічний конструкт, а як одна з двох рівноцінних наукових точок зору, що нібито досі конкурують:
"У науковій літературі маємо дві точки зору щодо походження української мови:
1. Початок формування української мови пов’язується з "давньоруською мовою" [...] східних слов’ян, які населяли Київську Русь. Цю точку зору визнавали й визнають мовознавці різних епох, а саме: О. Востоков, І. Срезневський, О. Потебня, О. Соболевський, О. Шахматов, Л. Васильєв, М. Дурново, Б. Ляпунов, Г. Ільїнський, Л. Булаховський, А. Селищев, С. Обнорський, М. Грунський, В. Виноградов, Р. Аванесов, П. Кузнецов, В. Борковський, Ф. Філін, М. Жовтобрюх, В. Колесов, В. Марков [...] Давньоруська мова функціонувала паралельно з церковнослов’янською, причина панування якої полягала в настановах давньоруських книжників, котрі вважали, що живе народне мовлення не слід відбивати в священній церковній книзі [Русский язик: энциклопедия, 1979, с. 10].
2. Розвиток східнослов’янських мов (української) відбувався безпосередньо з відповідних діалектів праслов’янської. Цей погляд обстоювали й обстоюють С. Смаль-Стоцький, Є. Тимченко, Ю. Шевельов, В. Русанівський та інші науковці".
(А. Зинякова, С. Пономаренко. Історія української мови: Загальні питання історії української мови. Історична фонетика: навчальний посібник для студентів філологічних факультетів вищих навчальних закладів, 2017).
Мало того, що автори підручника не згадали про суть теорії Ю. Шевельова (за якою розвиток української мови відбувся не "безпосередньо з діалектів праслов’янської", а через розщеплення києво-поліських діалектів і об'єднання однієї частини з галицько-подільськими), а приписали йому цю спрощену альтернативу, – вони, представивши "дві точки зору" як рівноправні, підсумовують усе висновком Кості Михальчука з 1884 (!) року: "повна реставрація правди дожидає ще свого розумного робітника".
⁵⁵ З новіших підручників молодшого покоління європейських славістів можна згадати, напр.: Matej Šekli "Tipologija lingvogenez slovanskih jezikov", 2018, 505 р.
Для ілюстрації використано картину «Стрічки» Ганни Криволап.
Для побудови мап використано шаблон OLA
28.10.2025